


Complete AI Pipeline for Cement Compressive Strength Prediction:
Industrial Best Practices & Real-World Case Studies
This article is written by a FuzzyFrog engineer with experience building AI tools for industries. Discover how AI can be applied on-site, its benefits, and its limitations. We test and refine, so you can act with clarity, save time, and get better results.
FuzzyFrog Team
15 de septiembre, 2025

Key Takeaways
- The trade-off between model accuracy and interpretability is managed by business needs. Prioritize interpretability when human oversight or audits are required, and prioritize accuracy when automation is the primary goal.
- An ML project doesn't end with accuracy. The real metric is the impact on efficiency, costs, and decision-making.
Industry Context & Problem Definition
1.1 What is cement?
Cement is one of the most used materials in construction, as it plays an important role in the production of concrete. Cement itself is a fine powder that, when mixed with water and aggregates like sand and gravel, forms concrete.
It's not uncommon, then, for studies to be conducted to understand the quality of this material. One of the projects we worked on1 involved understanding how cement composition impacts its strength.
Each section, question, and finding in this and other projects in the portfolio contrasts recent studies with the experience gained from carrying out the project.
1 Disclaimer: The series of projects in this portfolio is inspired by real-life projects carried out in business or academic contexts. However, due to confidentiality and ethical concerns, the information presented does not reveal names, data, or specific use cases. Fortunately, this does not dilute the experience we share with you.
1.2 What is cement made of?
Cement is composed of different chemical compounds, and the proportions in which they are combined create different types of cement. The components of cement are:
- Clinker (Silica, Alumina, Iron Oxide, Lime, Gypsum, Magnesia, Alkali)
- Gypsum
- Limestone
- Calcined Clay
- Slag
- etc.
Depending on the processes of different companies, these components vary in proportion.
1.3 How can Artificial Intelligence be applied to concrete design?
The implementation of AI must be guided by answering the question: How do I benefit from AI? From experience, the most direct way in which companies can benefit lies in one of the three pillars of any company (at a very abstract level, and depending on the company, each department could be categorized in any of them): Marketing, Customer Service, and Operations.
For this particular project, the client wanted to answer the question: How can I know the percentage of cement chemical compounds (not concrete per se) required to achieve a specific compressive strength? This case is illustrated in Figure 1.
Figure 1
Concrete Mix Design Compressive Strength Analysis
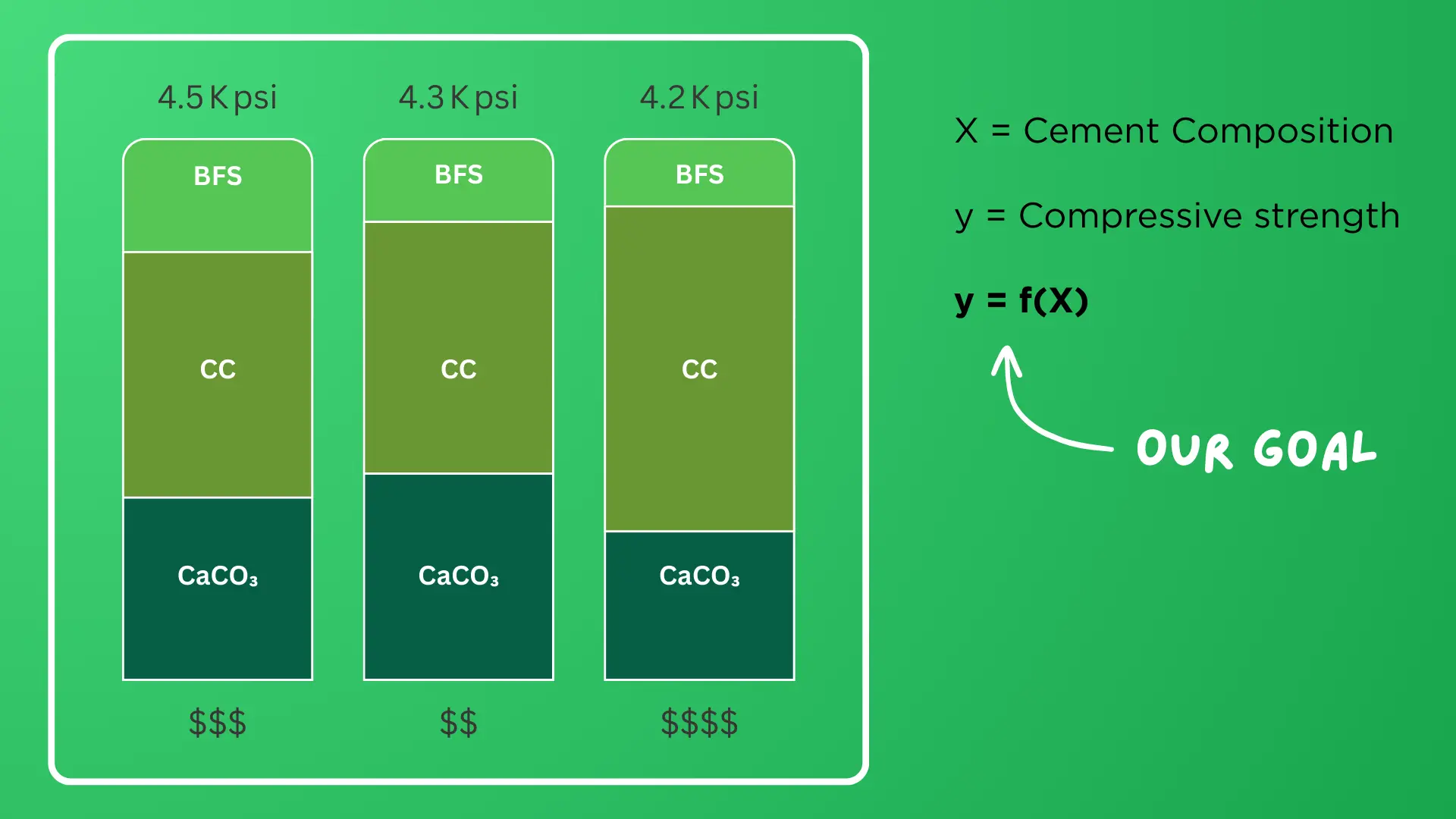
Note: Comparative analysis of three cement blend compositions containing blast furnace slag (BFS), cement clinker (CC), and calcium carbonate (CaCO₃). Bar charts show compressive strength values (4.2–4.5 Kpsi) and relative costs (−- −$$$) for different mix proportions. The objective function y = f(X) represents the relationship between cement composition (X) and resulting compressive strength (y) for material optimization.
Limestone has a direct effect on compressive strength. Several studies confirm this, providing evidence that supports the operational sense of the project as a cost-saving strategy. Recent findings demonstrate that limestone calcined clay cement mixtures can be optimized for both performance and sustainability (Chen, Chen, Li, & Zhang, 2025). Additionally, research shows that the fineness of limestone powder significantly impacts the mechanical performance of concrete (Zhang, Yang, Wu, Yu, Pang, & Lv, 2025).
Other ongoing initiatives to apply artificial intelligence (AI) in the design of concrete (not to be confused with cement), with the goal of optimizing both performance and sustainability (ZKG, n.d.; Concrete.ai, n.d.).
One major direction is the optimization of clinker content, where AI and high-performance computing accelerate materials discovery and improve predictive accuracy (Pyzer-Knapp et al., 2022).
Furthermore, recent studies on limestone calcined clay cement (LC3) have developed explainable multilayer machine learning models using more than 4,000 data points. These models reliably estimate the 28-day compressive strength of LC3 composites, surpassing the limitations of previous statistical approaches and conventional ML applications (Mercatus Center, 2023; MIT Technology Review, 2024).
1.4 What are the most common challenges construction companies face when implementing AI for cement quality prediction in real manufacturing environments?
Each company, depending on its maturity, faces different challenges. One of the most frequent challenges we have faced in companies when implementing AI solutions is data governance. More about this can be seen in another project [link to another project].
Another frequent challenge is the desire to start big. In practice, it is common for AI initiatives in small and medium-sized enterprises (and sometimes in large companies as well) to begin with staff who want to start the project internally. As a result, the data available at the beginning of the project often comes in simple formats like .xlsx or .csv. At this stage, building a complete pipeline is rarely justified for a prototype or pilot test.
Other challenges have also been highlighted in recent studies. These include concerns about the reliability and accuracy of algorithms, the cost per unit of output, and the difficulty of reverting to traditional procedures in case of technology failure or inaccessibility (Waqar, Bheel, & Tayeh, 2024).
In this article, we are not referring to AI implementation in the sense of using LLM-based agents, but rather domain-specific AI. However, other studies have documented challenges related to the implementation of generative AI in the construction industry.
These challenges include: domain knowledge — the vast specialized context of construction makes it difficult for GenAI to extract meaningful structure–activity relationships from industrial data; hallucinations — GenAI systems produce aesthetically convincing but inaccurate predictions with unjustified confidence, such as erroneous critical path schedules; accuracy — the lack of fundamental engineering knowledge leads models to capture only superficial statistical associations rather than causal foundations, risking faulty construction decisions; and cost — the high resource demands and continuous costs are major barriers, especially for small firms with limited budgets (Ghimire, Kim, & Acharya, 2024).
1.2 Which specific cement composition variables (clinker ratios, gypsum percentages, additives) have proven most predictive in recent industrial AI projects?
In industrial AI projects, the most predictive cement composition variables often depend on the dataset and target problem. For compressive strength prediction, key drivers usually include Clinker I (%), Gypsum (%), Limestone (%), and Calcined Clay (%). These variables consistently show strong correlations with early- and late-age strength (1, 3, 7, 28 days). A summary of these predictive variables is shown in Table 1.
Table 1
Most predictive cement composition variables in industrial AI projects.
| Variable | Most Predictive For | Notes | Feature Importance Approach |
|---|---|---|---|
| Clinker I (%) | Early strength (1–7 days) | Drives initial hydration reactions; higher clinker generally increases early PSI | Tree-based importance, SHAP |
| Gypsum (%) | Setting time & 1-day strength | Balances early hydration, prevents flash set | Tree-based importance, Lasso coefficients |
| Limestone (%) | 7–28 day strength | Fills voids, improves long-term strength and workability | Tree-based importance, permutation importance |
| Calcined Clay (%) | 28-day strength | Enhances pozzolanic reactions, boosts late-age compressive strength | Tree-based importance, SHAP |
| Other Additives | Minor/moderate effect | Plasticizers, slag, fly ash influence workability and strength moderately | Tree-based importance, ablation studies |
Note: This table summarizes the key cement composition variables that have proven most predictive for compressive strength in industrial AI projects. It highlights the influence of Clinker I, Gypsum, Limestone, Calcined Clay, and other additives. Feature importance was assessed using tree-based models and other statistical approaches. Own elaboration.
1.3 How do companies justify ROI for cement strength AI projects beyond model accuracy, and what metrics are typically monitored?
For this project, the client’s main goal was to optimize limestone usage in their cement blends. Operationally, this was the most important factor. Model accuracy was secondary to actionable insights.
The focus was on identifying how different composition variables affect compressive strength. By understanding these relationships, the team could suggest adjustments to reduce limestone content without sacrificing strength.
The recommendation for the client was to decide on target strength ranges first. Then, monitor key variables and iteratively test adjustments. This approach helps improve efficiency and supports clear business decisions.
2. Real-World Datasets and Data Handling
KeyTakeaway: -
2.1 What publicly available and proprietary datasets are actually used by professionals for AI training and validation?
In the best case, companies use proprietary datasets. One advantage is not only the competitive moat (e.g., quality data that others cannot access) but also having context in which the data was collected. This context allows for faster and more precise identification of outliers, predictive variables, and other nuances.
Alternatively, open datasets can be used as proxies while proprietary data is collected. The table below compares some publicly available datasets for this purpose (Table 2).
As a data engineer in the cement industry, the challenge is to understand how cement composition—not concrete mixtures—affects compressive strength, even without proprietary industrial data. These proxies allow iterative model refinement, multi-output prediction, and preliminary formulation insights before on-site measurements.
Table 2.
Publicly available datasets used as proxies for AI training and validation in cement compressive strength prediction.
| Dataset | Records | Variables | Pros as Proxy | Cons as Proxy | Best Use |
|---|---|---|---|---|---|
| UCI Concrete Compressive Strength | 1,030 | 8 inputs + 1 output | ✅ Well-established ✅ Widely used ✅ Clean data ✅ Standard benchmark | ❌ Based on Yeh (1998) ❌ Only conventional concrete ❌ Limited modern additives | Initial baseline, architecture validation, model comparison |
| Mendeley - Normal Concrete Dataset | ~500–1,000 | 9 features | ✅ Recent data (2022) ✅ Includes slump ✅ Real industrial source ✅ Modern additives | ❌ Geographically limited ❌ Single source ❌ Less established | Industrial proxy, validation with current data, multi-objective (slump + strength) |
| Figshare - High Performance Concrete | 597 (strength), 282 (slump), 264 (resistivity) | Multiple outputs | ✅ HPC-specific ✅ Multi-property ✅ Recent experimental data ✅ Electrical resistivity | ❌ Smaller size ❌ Less documented ❌ Possible inconsistency across sources | Specialized HPC, multi-objective prediction, advanced validation |
| Mendeley - IIT Bhubaneswar | 188 mixes | Recycled material variables | ✅ Concrete with recycled aggregates ✅ Wide w/b range (0.25–0.75) ✅ Controlled lab ✅ Modern additives (GGBS, MK) | ❌ Small size ❌ Geographic bias ❌ Focused on RCA | Sustainable concrete, recycled aggregates, proof of concept |
| Mendeley - Geopolymer Concrete | Variable | Geopolymers | ✅ Emerging technology ✅ Different chemistries ✅ Fresh experimental data | ❌ Very specific ❌ Not transferable ❌ Limited size | Alternative concretes, specialized research, specific niches |
Note: Comparison of publicly available datasets used as proxies for cement composition AI projects, highlighting record counts, variable coverage, pros, cons, and suggested use cases. Own elaboration.
4. Model Selection and Implementation
KeyTakeaway: -
2.2 How do data scientists handle missing measurements, inconsistent testing protocols, and outliers in cement lab datasets?
After defining the use case and collecting the dataset, it’s time to prepare it. In this how-to-guide, here’s what we usually do from experience:
STEP 1. Qualitative assessment of each variable
Meet with the data owner (the one with the most knowledge about how it was collected). We use a traffic-light scheme to rate the predictive value of each variable: Red for irrelevant, Amber for uncertain, and Green for highly useful variables. This step helps design experiments with valuable expert insight.
STEP 2. Review variable types
In Python, variables can be integers, floats, or objects (usually text, i.e., categorical).
STEP 3. Check for outliers and missing values
Outliers can be filtered, and missing values can be imputed. Expert judgment is key here. Context from STEP 1 guides the right decision. [Example in another project]
STEP 4. Compute the FDSR heuristic
FDSR = \(\frac{\text{Number of samples}}{k \times \text{Number of features}}\)
Where:
- Number of samples = total number of lab measurements
- Number of features = total variables included
- k = multiplier (5–10, depending on how cautious you are about overfitting)
Interpretation:
- FDSR ≥ 1 → ✅ Enough data for the features
- FDSR < 1 → ⚠️ Data diluted; consider dimensionality reduction or regularization
- FDSR → 0 → ❌ High risk of overfitting; reduce features or collect more data
Example: 100 features, k = 5 → minimum samples = 500 300 samples → FDSR = 300 / 500 = 0.6 → partial sufficiency, maybe apply PCA or select top features 600 samples → FDSR = 600 / 500 = 1.2 → good, all features safely included
STEP 5. Encode variables
Decide between one-hot, ordinal, or transformations to reduce dimensionality and avoid the curse of dimensionality.
STEP 6. Dataset ready for use
Once variables are selected and encoded, the dataset is ready for modeling.
As the number of features increases, the feature space expands exponentially. A widely cited rule of thumb suggests at least 5 samples per feature to reduce overfitting. Dimensionality reduction techniques like PCA or feature selection, as well as regularization (Lasso/Ridge), help maintain reliable model training. Reference: Curse of Dimensionality
2.3 What sample sizes and measurement frequencies yield reliable models in industrial cement prediction projects?
Why this question matters: Knowing the right sample size and measurement frequency is critical to ensure that AI models in cement prediction are reliable and actionable. Too few samples or irregular measurements can lead to overfitting, poor generalization, or misleading insights.
In our case, the client did not provide additional context or metadata beyond the raw data. The dataset included:
- Intervals of 7–8 hours between measurements
- Approximately 3 measurements per day
- Average sampling frequency: ~3 samples/day
Answering this question helps define whether the existing data is sufficient for training, or if additional sampling or resampling strategies are needed before deploying predictive models. It also informs decisions on model complexity, feature selection, and reliability thresholds.
3. Preprocessing and Feature Engineering
3.1 Which preprocessing steps best handle curing times, temperature variations, and equipment-related noise in cement datasets?
For cement datasets, preprocessing can be very complex, considering curing times, temperature variations, and equipment-related noise. These factors often require normalization, smoothing, or calibration across batches and instruments.
For this project, we took a simpler approach: we used curing times (setting times) directly and removed outlier measurements to minimize potential equipment noise. This ensured cleaner data for model training without overcomplicating preprocessing.
In another project [link], results from multiple laboratories were analyzed in detail to determine material quantities, and equipment noise was carefully accounted for. That study provides a reference for more advanced handling when data quality and variability are higher.
4. Model Selection and Implementation
KeyTakeaway: -
4.1 Which regression algorithms (Linear, Random Forest, XGBoost, neural networks) deliver the best ROI in cement prediction projects?
Table 3 summarizes the main regression algorithms used in cement prediction projects, along with their strengths, weaknesses, typical ROI drivers, and notes for operational application.
Table 3. Key regression algorithms and their ROI characteristics in industrial cement prediction projects.
| Algorithm | Strengths | Weaknesses | Typical ROI Drivers | Notes |
|---|---|---|---|---|
| Linear Regression | Simple, interpretable, fast to train | Limited capture of nonlinear effects | Quick insights with minimal compute | Good baseline; interpretable for plant managers |
| Random Forest | Handles nonlinear relationships, robust to outliers | Slower training, less interpretable than linear | Accuracy gains in complex compositions | Feature importance useful for operational decisions |
| XGBoost | High predictive accuracy, handles missing data | Longer training, hyperparameter tuning required | High ROI if prediction errors translate to material savings | Often used with feature selection or ablation studies |
| Neural Networks | Captures complex nonlinear interactions | Black-box, needs lots of data, risk of overfitting | Potentially high ROI in large datasets with complex features | Requires careful design; interpretability tools recommended (SHAP, LIME) |
Note: Own elaboration based on project experience and literature review.
4.2 How is the trade-off between model accuracy and interpretability handled for plant managers and quality teams?
This question is critical. Should a model prioritize interpretability or predictive power? As seen in section 1.1, AI can be applied broadly across marketing, customer service, and operations. The business decision drives the choice: if the AI system guides decision-makers, interpretability is paramount. If decisions are largely automated, interpretability may be less critical.
For example, in a previous financial project, regulatory authorities required a clear explanation of how the model reached its decisions. Similarly, in cement operations, plant managers and quality teams benefit from models whose outputs can be traced and justified.
While these three areas are not exclusive, they are often the primary domains where AI can generate meaningful impact. Balancing accuracy with interpretability ensures that AI insights are actionable and trusted by operational teams.
5. Validation, Benchmarking, and Industrial Deployment
KeyTakeaway: -
5. Validation, Benchmarking, and Industrial Deployment
5.1 How do companies validate AI models across seasonal variations and raw material suppliers?
| Validation Factor | Why It Matters | Typical Strategy | Example in Cement Plants |
|---|---|---|---|
| Seasonal temperature & humidity | Affect setting and strength | Cross-validation segmented by season | Models trained on summer vs winter data |
| Raw material suppliers | Different clinker/gypsum sources affect variability | Benchmarks separated by supplier | Hyperparameter tuning per clinker batch |
| Production shifts | Operators and equipment introduce noise | Validation splits by shift or production line | Day vs night shift performance comparison |
| Geographic sites | Plants in different regions | Federated validation / transfer learning | Model adjusted with sister-plant data |
5.2 How are AI predictions benchmarked against traditional lab tests, and which accuracy thresholds are acceptable?
📊 Benchmark Reference
Lab test: ASTM C109 compressive strength at 1, 7, 28 days
AI benchmark: RMSE < 3–5 MPa
⚖️ Acceptable Thresholds
R&D: R² ≥ 0.80, MAE ≤ 5%
Production: R² ≥ 0.90, RMSE ≤ 2–3 MPa
⏱️ Time Savings
Lab tests: 7–28 days per sample
AI prediction: near real-time (<1 min)
💰 ROI Impact
15–20% reduction in testing costs when AI replaces ~30% of physical tests
5.3 What are the main challenges and solutions for integrating prediction models into plant management systems?
Q: How do we connect AI models to existing SCADA/MES systems?
A: Use middleware APIs or OPC-UA connectors. Start with CSV exports before real-time integration.
Q: What if operators don’t trust the model outputs?
A: Provide explainability dashboards (e.g., SHAP) and run models in shadow mode first.
Q: How do we handle real-time inference speed?
A: Deploy lightweight models (RF, XGBoost) as microservices; neural nets only with GPU support.
Q: How do we manage downtime or system failure?
A: Always keep a fallback: revert to lab tests or last validated model checkpoint.
5.4 How is continuous model retraining and monitoring implemented in production environments?
- Data Collection: Automate ingestion of lab, sensor, and production data.
- Monitoring for Drift: Dashboards track RMSE/MAE vs lab tests; alerts if deviation >10%.
- Retraining Strategy: Weekly mini-batch retraining; incremental updates for trees; periodic full retraining for deep nets.
- CI/CD Pipeline: Use MLOps tools (MLflow, Kubeflow, Airflow) for versioning, validation, and deployment.
- Human-in-the-loop Approval: Quality managers review models before production rollout.
6. Emerging Trends and Future Applications
6.1 Which emerging AI technologies are being piloted for cement quality prediction?
Physics-Informed Neural Networks (PINNs): Combine hydration kinetics and heat transfer equations with data-driven learning, improving extrapolation to unseen curing conditions.
Graph Neural Networks (GNNs): Capture interactions between cement particles and admixtures for finer microstructure predictions.
Federated Learning: Enables multi-plant training without sharing proprietary data; valuable for corporations with multiple sites.
Generative Models: Used to propose new formulations balancing cost, CO₂ footprint, and strength.
Figure 2
Timeline of emerging AI technologies for cement quality prediction

6.2 How are AI predictions used to optimize raw material procurement, reduce production costs, and improve sustainability?
-
🏗️ Raw Material Procurement:
AI forecasts demand and strength requirements, avoids over-purchasing, and supports supplier negotiations.
- Forecast demand and strength needs in advance
- Avoid excess clinker or gypsum purchases
- Negotiate better with suppliers using predictive usage trends
-
💰 Cost Reduction:
Optimize material substitution, reduce admixture dependency, and automate mix design.
- Substitute limestone while maintaining compressive strength
- Reduce reliance on costly admixtures via composition balancing
- Automate mix design to lower lab testing expenses
-
🌍 Sustainability:
Lower clinker factor, validate alternative blends, and minimize waste.
- Reduce clinker factor → lower CO₂ emissions
- Validate LC3 and geopolymer blends faster with AI
- Cut down waste from failed batches using early predictions
References
Chen, X., Chen, W., Li, Z., & Zhang, P. (2025). A hybrid prediction and multi-objective optimization framework for limestone calcined clay cement concrete mixture design. Scientific Reports, 15, 22120. https://doi.org/10.1038/s41598-025-05288-3
Zhang, M., Yang, Y., Wu, Y., Yu, J., Pang, H., & Lv, H. (2025). Effect of limestone powder fineness on the physical and mechanical performance of concrete. Frontiers in Materials. https://pmc.ncbi.nlm.nih.gov/articles/PMC11857451/
Waqar, A., Bheel, N., & Tayeh, B. A. (2024). Modeling the effect of implementation of artificial intelligence powered image analysis and pattern recognition algorithms in concrete industry. Developments in the Built Environment, 17, 100349. https://doi.org/10.1016/j.dibe.2024.100349
Ghimire, P., Kim, K., & Acharya, M. (2024). Opportunities and challenges of generative AI in construction industry: Focusing on adoption of text-based models. Buildings, 14(1), 220. https://doi.org/10.3390/buildings14010220
Concrete.ai. (n.d.). Concrete AI. Retrieved August 25, 2025, from https://www.concrete.ai/
Mercatus Center. (2023). Future of materials science: AI, automation, and policy strategies. Retrieved August 25, 2025, from https://www.mercatus.org/research/policy-briefs/future-materials-science-ai-automation-and-policy-strategies
MIT Technology Review. (2024, December 12). Why materials science is key to unlocking the next frontier of AI development. Retrieved August 25, 2025, from https://www.technologyreview.com/2024/12/12/1107976/why-materials-science-is-key-to-unlocking-the-next-frontier-of-ai-development/
Pyzer-Knapp, E. O., Pitera, J. W., Staar, P. W., Takeda, S., Laino, T., Sanders, D. P., ... & Curioni, A. (2022). Accelerating materials discovery using artificial intelligence, high performance computing and robotics. npj Computational Materials, 8(1), 84. https://doi.org/10.1038/s41524-022-00765-z
ZKG. (n.d.). Optimizing cement strength. Retrieved August 25, 2025, from https://www.zkg.de/en/artikel/zkg_Optimizing_cement_strength-3612610.html
Dr. Alan López
Senior ML Engineer & Product Researcher
PhD in Sciences • Mechatronics Engineer
Alan has 10 years of experience in AI and computer vision, combining academic and business approaches. He has led projects in the automotive and financial industries, specializing in bio-inspired algorithms, computer vision, and electronic failure prediction. His research, published in indexed journals, has generated concrete results in computer vision and investment portfolio optimization.

Profile

Ideas

Articles
