
Educación
Evaluación de Modelos
Aprende a evaluar tus modelos de ML, elegir métricas y evitar errores en decisiones.




Jump Smart, Think Fuzzy
Ready to jump smart?
Este artículo está escrito por un ingeniero de FuzzyFrog con experiencia en la construcción de herramientas de IA para industrias. Descubre cómo se puede aplicar la IA en sitio, sus beneficios y sus limitaciones.
Probamos y refinamos, para que puedas actuar con claridad, ahorrar tiempo y obtener mejores resultados.
Equipo FuzzyFrog
15 de septiembre, 2025
El cemento es uno de los materiales más utilizados en la construcción, ya que desempeña un papel importante en la producción de concreto. El cemento en sí es un polvo fino que, al mezclarse con agua y agregados como arena y grava, forma concreto.
No es raro, entonces, que se realicen estudios para comprender la calidad de este material. Uno de los proyectos en los que trabajamos1 consistió en entender cómo la composición del cemento impacta su resistencia.
Cada sección, pregunta y hallazgo en este y otros proyectos del portafolio contrasta estudios recientes con la experiencia adquirida al llevar a cabo el proyecto.
1 Disclaimer: La serie de proyectos de este portafolio se inspira en proyectos reales realizados en contextos empresariales o académicos. Sin embargo, debido a preocupaciones de confidencialidad y ética, la información presentada no revela nombres, datos ni casos de uso específicos. Afortunadamente, esto no diluye la experiencia que compartimos contigo.
El cemento está compuesto por diferentes compuestos químicos, y las proporciones en que se combinan crean distintos tipos de cemento. Los componentes del cemento son:
Dependiendo de los procesos de cada empresa, estos componentes varían en proporción.
La implementación de IA debe guiarse respondiendo a la pregunta: ¿Cómo me beneficia la IA? Según la experiencia, la manera más directa en que las empresas pueden beneficiarse se encuentra en uno de los tres pilares de cualquier empresa (a un nivel muy abstracto, y dependiendo de la empresa, cada departamento podría clasificarse en cualquiera de ellos): Marketing, Atención al Cliente y Operaciones.
Para este proyecto en particular, el cliente quería responder a la pregunta: ¿Cómo puedo conocer el porcentaje de compuestos químicos del cemento (no del concreto en sí) requerido para alcanzar una resistencia a compresión específica? Este caso se ilustra en Figura 1.
Figura 1
Análisis de Resistencia a Compresión en el Diseño de Mezclas de Concreto
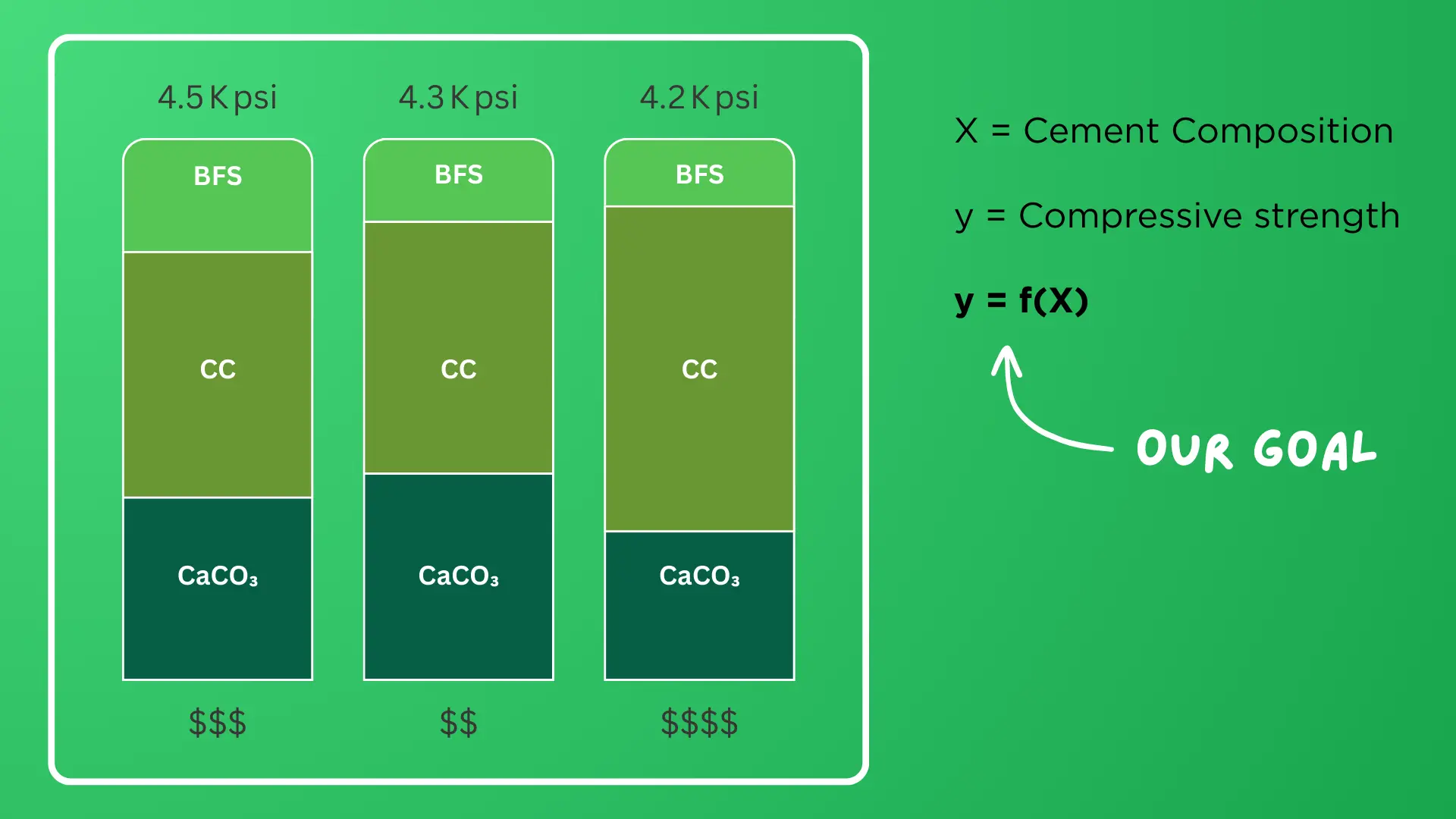
Nota: Análisis comparativo de tres composiciones de mezclas de cemento que contienen escoria de alto horno (BFS), clinker de cemento (CC) y carbonato de calcio (CaCO₃). Los gráficos de barras muestran valores de resistencia a compresión (4.2–4.5 Kpsi) y costos relativos (−- −$$$) para diferentes proporciones de mezcla. La función objetivo y = f(X) representa la relación entre la composición del cemento (X) y la resistencia a compresión resultante (y) para la optimización de materiales.
La piedra caliza tiene un efecto directo en la resistencia a compresión. Varios estudios lo confirman, proporcionando evidencia que respalda el sentido operativo del proyecto como estrategia de ahorro de costos. Hallazgos recientes demuestran que las mezclas de cemento de arcilla calcinada y piedra caliza pueden optimizarse tanto para rendimiento como para sostenibilidad (Chen, Chen, Li, & Zhang, 2025). Además, la investigación muestra que la finura del polvo de piedra caliza impacta significativamente el desempeño mecánico del concreto (Zhang, Yang, Wu, Yu, Pang, & Lv, 2025).
Otras iniciativas en curso aplican inteligencia artificial (IA) en el diseño de concreto (no confundir con cemento), con el objetivo de optimizar tanto el rendimiento como la sostenibilidad (ZKG, n.d.; Concrete.ai, n.d.).
Una de las principales líneas de acción es la optimización del contenido de clinker, donde la IA y la computación de alto rendimiento aceleran el descubrimiento de materiales y mejoran la precisión predictiva (Pyzer-Knapp et al., 2022).
Además, estudios recientes sobre cemento de arcilla calcinada y piedra caliza (LC3) han desarrollado modelos de machine learning multilayer explicables usando más de 4,000 puntos de datos. Estos modelos estiman de manera confiable la resistencia a compresión a 28 días de los composites LC3, superando las limitaciones de enfoques estadísticos previos y aplicaciones convencionales de ML (Mercatus Center, 2023; MIT Technology Review, 2024).
Cada empresa, dependiendo de su madurez, enfrenta diferentes desafíos. Uno de los más frecuentes al implementar soluciones de IA es la gobernanza de datos. Más información se puede ver en otro proyecto [enlace a otro proyecto].
Otro desafío frecuente es el deseo de comenzar en grande. En la práctica, es común que las iniciativas de IA en PYMEs (y a veces en grandes empresas también) comiencen con personal que quiere iniciar el proyecto internamente. Como resultado, los datos disponibles al inicio suelen estar en formatos simples como .xlsx o .csv. En esta etapa, construir un pipeline completo rara vez se justifica para un prototipo o prueba piloto.
Otros desafíos también se han destacado en estudios recientes, incluyendo preocupaciones sobre la fiabilidad y precisión de los algoritmos, el costo por unidad de producción y la dificultad de volver a los procedimientos tradicionales en caso de falla tecnológica o inaccesibilidad (Waqar, Bheel, & Tayeh, 2024).
En este artículo, no nos referimos a la implementación de IA en el sentido de usar agentes basados en LLM, sino a IA específica del dominio. Sin embargo, otros estudios han documentado desafíos relacionados con la implementación de IA generativa en la industria de la construcción.
Estos desafíos incluyen: conocimiento del dominio — el vasto contexto especializado de la construcción dificulta que GenAI extraiga relaciones significativas de estructura-actividad a partir de datos industriales; alucinaciones — los sistemas GenAI producen predicciones estéticamente convincentes pero inexactas con confianza injustificada, como cronogramas de ruta crítica erróneos; precisión — la falta de conocimiento de ingeniería fundamental lleva a que los modelos capturen solo asociaciones estadísticas superficiales en lugar de fundamentos causales, arriesgando decisiones de construcción defectuosas; y costo — las altas demandas de recursos y costos continuos son barreras importantes, especialmente para pequeñas empresas con presupuestos limitados (Ghimire, Kim, & Acharya, 2024).
En proyectos industriales de IA, las variables de composición del cemento más predictivas dependen del conjunto de datos y del problema objetivo. Para la predicción de la resistencia a compresión, los factores clave suelen incluir Clinker I (%), Yeso (%), Piedra Caliza (%) y Arcilla Calcinada (%). Estas variables muestran consistentemente fuertes correlaciones con la resistencia a edades tempranas y tardías (1, 3, 7, 28 días). Un resumen de estas variables predictivas se muestra en Tabla 1.
Tabla 1
Variables de composición de cemento más predictivas en proyectos industriales de IA.
| Variable | Más Predictiva Para | Notas | Enfoque de Importancia de Característica |
|---|---|---|---|
| Clinker I (%) | Resistencia temprana (1–7 días) | Impulsa reacciones de hidratación inicial; mayor clinker generalmente aumenta PSI temprano | Importancia basada en árboles, SHAP |
| Yeso (%) | Tiempo de fraguado & resistencia a 1 día | Equilibra hidratación temprana, previene fraguado rápido | Importancia basada en árboles, coeficientes Lasso |
| Piedra Caliza (%) | Resistencia a 7–28 días | Rellena vacíos, mejora resistencia a largo plazo y trabajabilidad | Importancia basada en árboles, importancia por permutación |
| Arcilla Calcinada (%) | Resistencia a 28 días | Potencia reacciones puzolánicas, aumenta resistencia a compresión tardía | Importancia basada en árboles, SHAP |
| Otros Aditivos | Efecto menor/moderado | Plastificantes, escoria, cenizas volantes influyen moderadamente en trabajabilidad y resistencia | Importancia basada en árboles, estudios de ablación |
Nota: Esta tabla resume las variables clave de composición del cemento que han demostrado ser más predictivas para la resistencia a compresión en proyectos industriales de IA. Destaca la influencia de Clinker I, Yeso, Piedra Caliza, Arcilla Calcinada y otros aditivos. La importancia de las características se evaluó utilizando modelos basados en árboles y otros enfoques estadísticos. Elaboración propia.
Para este proyecto, el objetivo principal del cliente era optimizar el uso de piedra caliza en sus mezclas de cemento. Operativamente, este fue el factor más importante. La precisión del modelo era secundaria frente a los insights accionables.
El enfoque estaba en identificar cómo diferentes variables de composición afectan la resistencia a compresión. Al entender estas relaciones, el equipo podía sugerir ajustes para reducir el contenido de piedra caliza sin sacrificar resistencia.
La recomendación para el cliente fue decidir primero los rangos de resistencia objetivo. Luego, monitorear las variables clave y probar ajustes de manera iterativa. Este enfoque ayuda a mejorar la eficiencia y respalda decisiones empresariales claras.
En el mejor de los casos, las empresas utilizan conjuntos de datos propietarios. Una ventaja no es solo la barrera competitiva (por ejemplo, datos de calidad a los que otros no pueden acceder) sino también tener contexto sobre cómo se recopilaron los datos. Este contexto permite una identificación más rápida y precisa de valores atípicos, variables predictivas y otros matices.
Alternativamente, se pueden usar conjuntos de datos abiertos como proxies mientras se recopilan los datos propietarios. La tabla a continuación compara algunos conjuntos de datos públicos para este propósito (Tabla 2).
Como ingeniero de datos en la industria del cemento, el desafío es entender cómo la composición del cemento—no las mezclas de concreto—afecta la resistencia a compresión, incluso sin datos industriales propietarios. Estos proxies permiten refinar modelos de manera iterativa, predicción multi-salida e insights preliminares de formulación antes de mediciones in situ.
Tabla 2.
Conjuntos de datos públicos usados como proxies para entrenamiento y validación de IA en la predicción de resistencia a compresión del cemento.
| Conjunto de Datos | Registros | Variables | Pros como Proxy | Contras como Proxy | Mejor Uso |
|---|---|---|---|---|---|
| UCI Resistencia a Compresión de Concreto | 1,030 | 8 entradas + 1 salida | ✅ Bien establecido ✅ Ampliamente usado ✅ Datos limpios ✅ Referencia estándar | ❌ Basado en Yeh (1998) ❌ Solo concreto convencional ❌ Aditivos modernos limitados | Línea base inicial, validación de arquitectura, comparación de modelos |
| Mendeley - Concreto Normal | ~500–1,000 | 9 características | ✅ Datos recientes (2022) ✅ Incluye asentamiento ✅ Fuente industrial real ✅ Aditivos modernos | ❌ Limitado geográficamente ❌ Fuente única ❌ Menos establecido | Proxy industrial, validación con datos actuales, multi-objetivo (asentamiento + resistencia) |
| Figshare - Concreto de Alto Rendimiento | 597 (resistencia), 282 (asentamiento), 264 (resistividad) | Múltiples salidas | ✅ Específico HPC ✅ Multi-propiedad ✅ Datos experimentales recientes ✅ Resistividad eléctrica | ❌ Tamaño más pequeño ❌ Menos documentado ❌ Posible inconsistencia entre fuentes | HPC especializado, predicción multi-objetivo, validación avanzada |
| Mendeley - IIT Bhubaneswar | 188 mezclas | Variables de materiales reciclados | ✅ Concreto con agregados reciclados ✅ Amplio rango agua/cemento (0.25–0.75) ✅ Laboratorio controlado ✅ Aditivos modernos (GGBS, MK) | ❌ Tamaño pequeño ❌ Sesgo geográfico ❌ Enfocado en RCA | Concreto sostenible, agregados reciclados, prueba de concepto |
| Mendeley - Concreto Geopolímero | Variable | Geopolímeros | ✅ Tecnología emergente ✅ Químicas diferentes ✅ Datos experimentales recientes | ❌ Muy específico ❌ No transferible ❌ Tamaño limitado | Concretos alternativos, investigación especializada, nichos específicos |
Nota: Comparación de conjuntos de datos públicos usados como proxies en proyectos de IA para composición de cemento, destacando cantidad de registros, cobertura de variables, pros, contras y casos de uso sugeridos. Elaboración propia.
Después de definir el caso de uso y recopilar el conjunto de datos, es momento de prepararlo. En esta guía práctica, esto es lo que usualmente hacemos según la experiencia:
PASO 1. Evaluación cualitativa de cada variable
Reunirse con el propietario de los datos (quien tenga más conocimiento sobre cómo se recopilaron). Usamos un esquema de semáforo para calificar el valor predictivo de cada variable: Rojo para irrelevante, Ámbar para incierta, y Verde para variables altamente útiles. Este paso ayuda a diseñar experimentos con información valiosa de expertos.
PASO 2. Revisar tipos de variables
En Python, las variables pueden ser enteros, flotantes u objetos (usualmente texto, es decir, categóricas).
PASO 3. Verificar valores atípicos y faltantes
Los valores atípicos pueden filtrarse, y los faltantes imputarse. El juicio experto es clave aquí. El contexto del PASO 1 guía la decisión correcta. [Ejemplo en otro proyecto]
PASO 4. Calcular la heurística FDSR
FDSR = \(\frac{\text{Número de muestras}}{k \times \text{Número de variables}}\)
Donde:
Interpretación:
Ejemplo: 100 variables, k = 5 → mínimo de muestras = 500 300 muestras → FDSR = 300 / 500 = 0.6 → suficiencia parcial, tal vez aplicar PCA o seleccionar las principales variables 600 muestras → FDSR = 600 / 500 = 1.2 → bueno, todas las variables incluidas de manera segura
PASO 5. Codificar variables
Decidir entre one-hot, ordinal o transformaciones para reducir dimensionalidad y evitar la maldición de la dimensionalidad.
PASO 6. Conjunto de datos listo para usar
Una vez seleccionadas y codificadas las variables, el conjunto de datos está listo para modelado.
A medida que aumenta el número de variables, el espacio de características se expande exponencialmente. Una regla práctica ampliamente citada sugiere al menos 5 muestras por variable para reducir sobreajuste. Técnicas de reducción de dimensionalidad como PCA o selección de variables, así como regularización (Lasso/Ridge), ayudan a mantener un entrenamiento de modelo confiable. Referencia: Maldición de la dimensionalidad
Por qué importa esta pregunta: Conocer el tamaño de muestra y la frecuencia de medición correctos es crítico para asegurar que los modelos de IA en predicción de cemento sean confiables y accionables. Pocas muestras o mediciones irregulares pueden causar sobreajuste, mala generalización o resultados engañosos.
En nuestro caso, el cliente no proporcionó contexto adicional ni metadatos más allá de los datos crudos. El conjunto de datos incluía:
Responder esta pregunta ayuda a definir si los datos existentes son suficientes para entrenamiento, o si se necesitan estrategias adicionales de muestreo o remuestreo antes de desplegar modelos predictivos. También informa decisiones sobre complejidad del modelo, selección de variables y umbrales de confiabilidad.
Para conjuntos de datos de cemento, el preprocesamiento puede ser muy complejo, considerando tiempos de fraguado, variaciones de temperatura y ruido de equipos. Estos factores a menudo requieren normalización, suavizado o calibración entre lotes e instrumentos.
Para este proyecto, tomamos un enfoque más simple: usamos directamente los tiempos de fraguado y eliminamos mediciones atípicas para minimizar el posible ruido de los equipos. Esto aseguró datos más limpios para el entrenamiento del modelo sin complicar demasiado el preprocesamiento.
En otro proyecto [enlace], se analizaron en detalle los resultados de múltiples laboratorios para determinar cantidades de material, y se tuvo en cuenta cuidadosamente el ruido de los equipos. Ese estudio sirve como referencia para un manejo más avanzado cuando la calidad y variabilidad de los datos son mayores.
La Tabla 3 resume los principales algoritmos de regresión utilizados en proyectos de predicción de cemento, junto con sus fortalezas, debilidades, impulsores típicos de ROI y notas para aplicación operacional.
| Factor de Validación | Por Qué Importa | Estrategia Típica | Ejemplo en Plantas de Cemento |
|---|---|---|---|
| Temperatura y humedad estacional | Afectan el fraguado y la resistencia | Validación cruzada segmentada por estación | Modelos entrenados con datos de verano vs invierno |
| Proveedores de materias primas | Diferentes fuentes de clinker/yeso afectan la variabilidad | Benchmarks separados por proveedor | Ajuste de hiperparámetros por lote de clinker |
| Turnos de producción | Operadores y equipos introducen ruido | Divisiones de validación por turno o línea de producción | Comparación de rendimiento turno diurno vs nocturno |
| Sitios geográficos | Plantas en diferentes regiones | Validación federada / transferencia de aprendizaje | Modelo ajustado con datos de plantas hermanas |
Prueba de laboratorio: resistencia a compresión ASTM C109 a 1, 7 y 28 días
Benchmark de IA: RMSE < 3–5 MPa
I+D: R² ≥ 0.80, MAE ≤ 5%
Producción: R² ≥ 0.90, RMSE ≤ 2–3 MPa
Pruebas de laboratorio: 7–28 días por muestra
Predicción de IA: casi en tiempo real (<1 min)
Reducción del 15–20% en costos de pruebas cuando la IA reemplaza ~30% de las pruebas físicas
P: ¿Cómo conectamos los modelos de IA con los sistemas SCADA/MES existentes?
R: Usar APIs de middleware o conectores OPC-UA. Empezar con exportaciones CSV antes de la integración en tiempo real.
P: ¿Qué pasa si los operadores no confían en los resultados del modelo?
R: Proporcionar paneles de explicabilidad (p. ej., SHAP) y ejecutar los modelos en modo sombra primero.
P: ¿Cómo manejamos la velocidad de inferencia en tiempo real?
R: Desplegar modelos livianos (RF, XGBoost) como microservicios; redes neuronales solo con soporte GPU.
P: ¿Cómo gestionamos el tiempo de inactividad o fallas del sistema?
R: Siempre mantener un respaldo: volver a pruebas de laboratorio o al último checkpoint validado del modelo.
Redes Neuronales Informadas por Física (PINNs): Combinan cinética de hidratación y ecuaciones de transferencia de calor con aprendizaje basado en datos, mejorando la extrapolación a condiciones de fraguado no observadas.
Redes Neuronales de Grafos (GNNs): Capturan interacciones entre partículas de cemento y aditivos para predicciones más precisas de la microestructura.
Aprendizaje Federado: Permite entrenar modelos en múltiples plantas sin compartir datos propietarios; valioso para corporaciones con varios sitios.
Modelos Generativos: Se utilizan para proponer nuevas formulaciones que equilibren costo, huella de CO₂ y resistencia.
Chen, X., Chen, W., Li, Z., & Zhang, P. (2025). A hybrid prediction and multi-objective optimization framework for limestone calcined clay cement concrete mixture design. Scientific Reports, 15, 22120. https://doi.org/10.1038/s41598-025-05288-3
Zhang, M., Yang, Y., Wu, Y., Yu, J., Pang, H., & Lv, H. (2025). Effect of limestone powder fineness on the physical and mechanical performance of concrete. Frontiers in Materials. https://pmc.ncbi.nlm.nih.gov/articles/PMC11857451/
Waqar, A., Bheel, N., & Tayeh, B. A. (2024). Modeling the effect of implementation of artificial intelligence powered image analysis and pattern recognition algorithms in concrete industry. Developments in the Built Environment, 17, 100349. https://doi.org/10.1016/j.dibe.2024.100349
Ghimire, P., Kim, K., & Acharya, M. (2024). Opportunities and challenges of generative AI in construction industry: Focusing on adoption of text-based models. Buildings, 14(1), 220. https://doi.org/10.3390/buildings14010220
Concrete.ai. (n.d.). Concrete AI. Retrieved August 25, 2025, from https://www.concrete.ai/
Mercatus Center. (2023). Future of materials science: AI, automation, and policy strategies. Retrieved August 25, 2025, from https://www.mercatus.org/research/policy-briefs/future-materials-science-ai-automation-and-policy-strategies
MIT Technology Review. (2024, December 12). Why materials science is key to unlocking the next frontier of AI development. Retrieved August 25, 2025, from https://www.technologyreview.com/2024/12/12/1107976/why-materials-science-is-key-to-unlocking-the-next-frontier-of-ai-development/
Pyzer-Knapp, E. O., Pitera, J. W., Staar, P. W., Takeda, S., Laino, T., Sanders, D. P., ... & Curioni, A. (2022). Accelerating materials discovery using artificial intelligence, high performance computing and robotics. npj Computational Materials, 8(1), 84. https://doi.org/10.1038/s41524-022-00765-z
ZKG. (n.d.). Optimizing cement strength. Retrieved August 25, 2025, from https://www.zkg.de/en/artikel/zkg_Optimizing_cement_strength-3612610.html
Senior ML Engineer & Product Researcher
Doctorado en Ciencias • Ingeniero en Mecatrónica
Alan tiene 10 años de experiencia en IA y visión artificial, combinando enfoque académico y empresarial. Ha liderado proyectos en la industria automotriz y financiera, especializado en algoritmos bioinspirados, visión por computadora y predicción de fallas electrónicas. Su investigación, publicada en revistas indexadas, ha generado resultados concretos en visión artificial y optimización de portafolios de inversión.

Perfil

Ideas

Artículos
Conecta con nuestros expertos para una consulta personalizada sobre cómo adaptar esta solución a tu caso específico.
Aprende a evaluar tus modelos de ML, elegir métricas y evitar errores en decisiones.

Folleto práctico para conseguir un rol en Ciencia de Datos y mejorar tus oportunidades.

Consejos prácticos para mejorar tu perfil y aumentar oportunidades en Ciencia de Datos.
