/ Mini-Labs / ¿Mi target está mal definido?
¿Mi target está mal definido?
Diagnóstico en 5 pasos para saber si vale la pena entrenar — o si primero necesitas redefinir el problema.
ContextoEl error que arruina el modelo antes de entrenarlo
Un target mal definido es el error más costoso en ML: el modelo aprende bien, las métricas se ven bien, y en producción no sirve. Sucede antes de escribir una sola línea de código.
- No puedes explicar la variable objetivo en una oración sin ambigüedad.
- El umbral de clasificación no tiene respaldo de negocio — es arbitrario.
- Dos personas con los mismos datos etiquetarían diferente los casos límite.
- La etiqueta depende de información que no tendrás disponible en producción.
- El desbalance de clases es extremo sin justificación real del fenómeno.
- El baseline más simple ya supera al modelo — señal de que el problema está mal planteado.
DatosQué buscar en tu dataset antes de fijar el target
El dataset revela si el target tiene sentido. Estos son los puntos de inspección mínimos antes de fijar la variable objetivo.
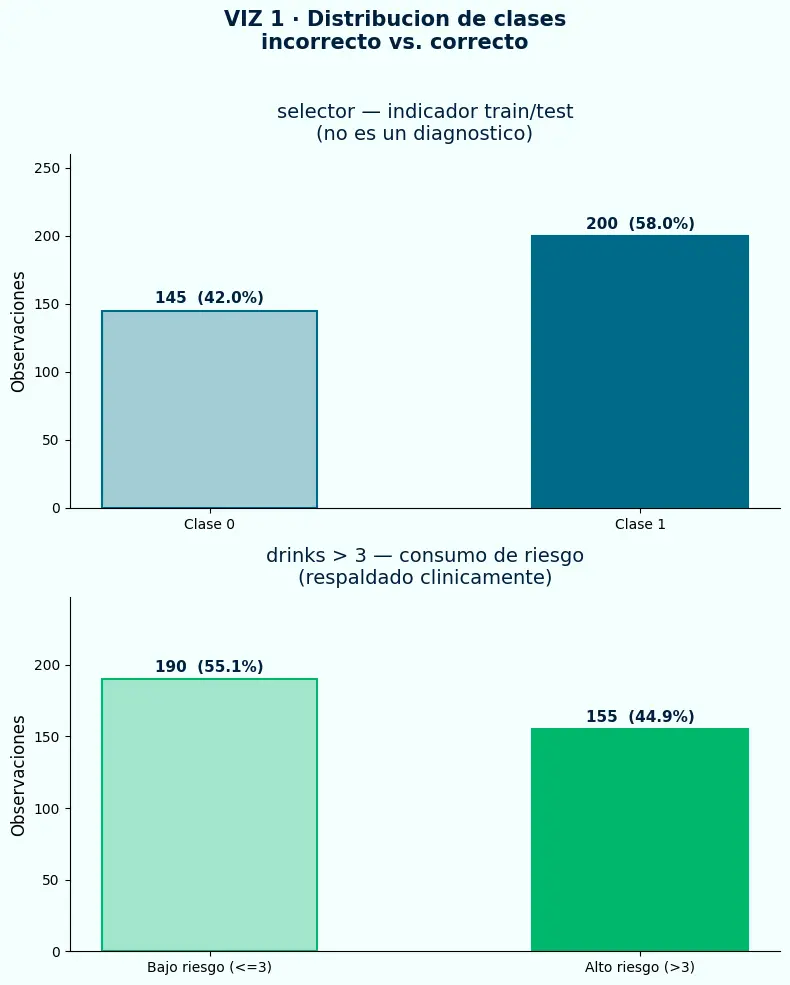
- El target incorrecto (
selector) tiene distribución 42/58 — razonable a primera vista, pero no representa ningún fenómeno clínico real. - El target correcto (
drinks > 3) tiene distribución 55/45 — balanceada y respaldada por guías clínicas de consumo de riesgo en varones. - Un desbalance mayor a 10:1 sin justificación es señal de alerta inmediata antes de fijar cualquier target.
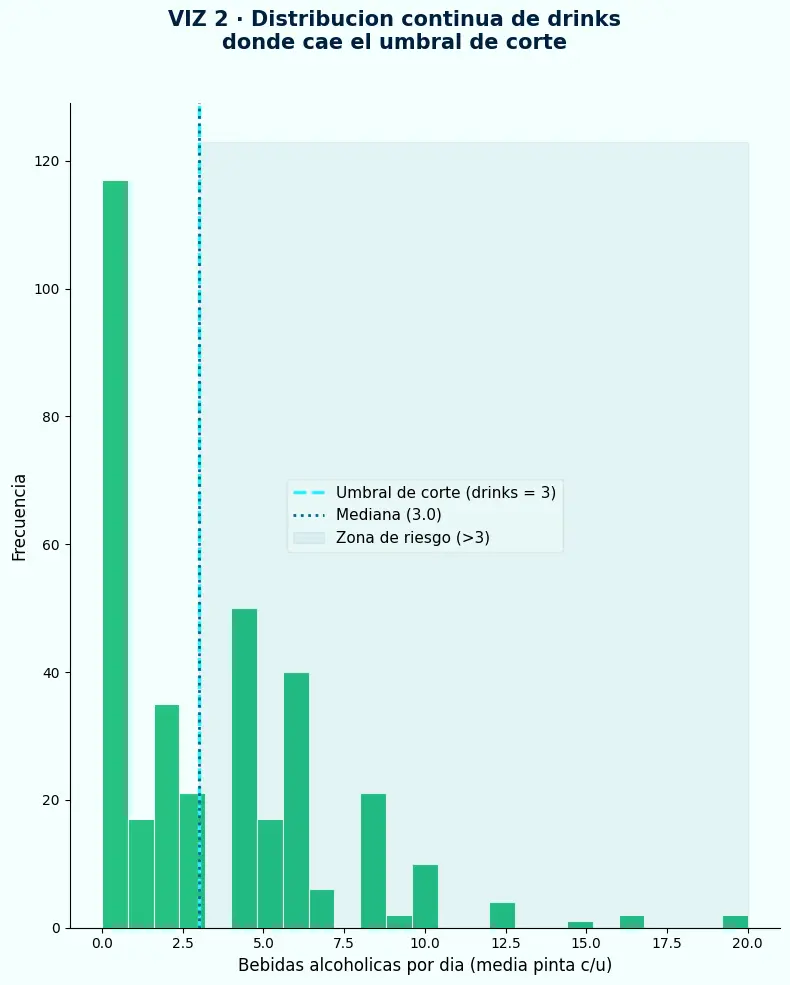
- Antes de binarizar, hay que verificar dónde cae el umbral en la distribución real — un corte en zona de alta densidad genera cientos de casos frontera ambiguos.
- La mediana está en 3.0 bebidas/día, exactamente en el umbral de corte — lo que confirma que el punto de división separa dos grupos con comportamiento distinto.
- La cola larga hacia la derecha (hasta 20 bebidas/día) indica outliers reales, no errores de captura — son pacientes con consumo crónico severo.
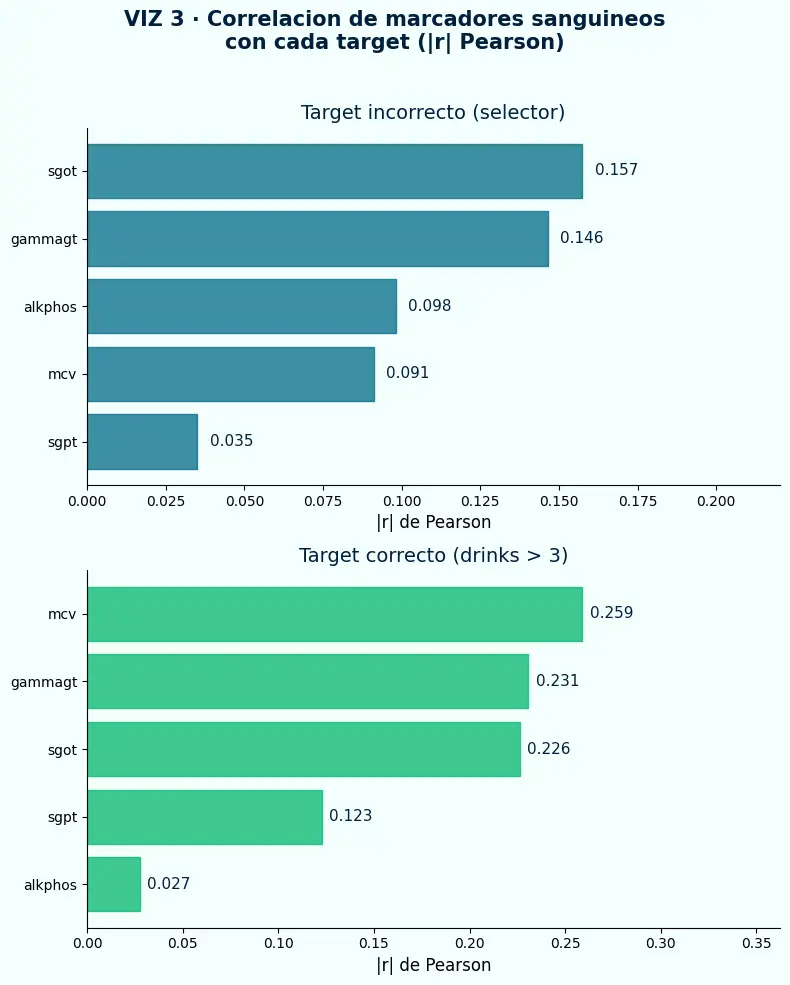
- Con el target incorrecto, el marcador más correlacionado alcanza r = 0.157 — una señal débil sin respaldo clínico interpretable.
- Con el target correcto, las correlaciones suben y el orden de los marcadores coincide con la literatura médica: mcv y gammagt lideran.
- Si el target correcto tuviera correlaciones cercanas a cero con todos los features, sería señal de que faltan variables o el umbral está mal elegido.
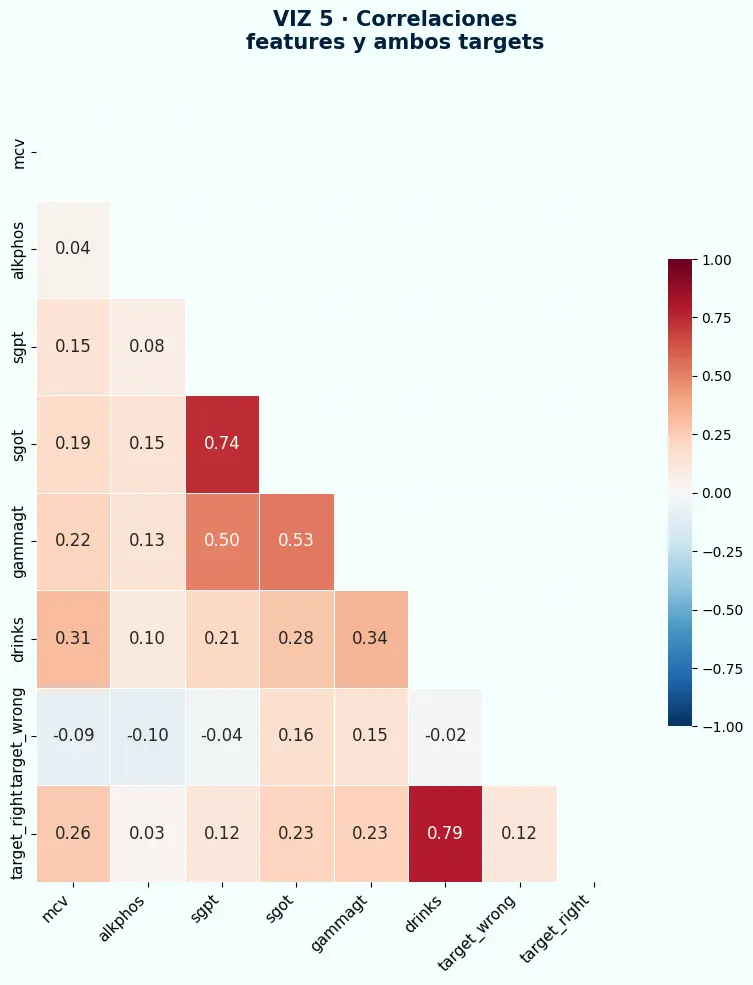
- La correlación entre
target_wrongydrinkses -0.02 — prácticamente cero. El target que usaron cientos de papers no tiene relación con la variable clínica que supuestamente medía. target_rightydrinkstienen correlación 0.79 — esperada, ya que el target se deriva directamente de esa variable.- sgot y sgpt tienen correlación 0.74 entre sí — colinealidad que el modelo debe manejar, no una señal de leakage.
ModeloCómo el target condiciona cada decisión de modelado
La definición del target no solo afecta las etiquetas — determina qué tipo de modelo construyes, qué métrica optimizas y cómo lo evalúas en producción.
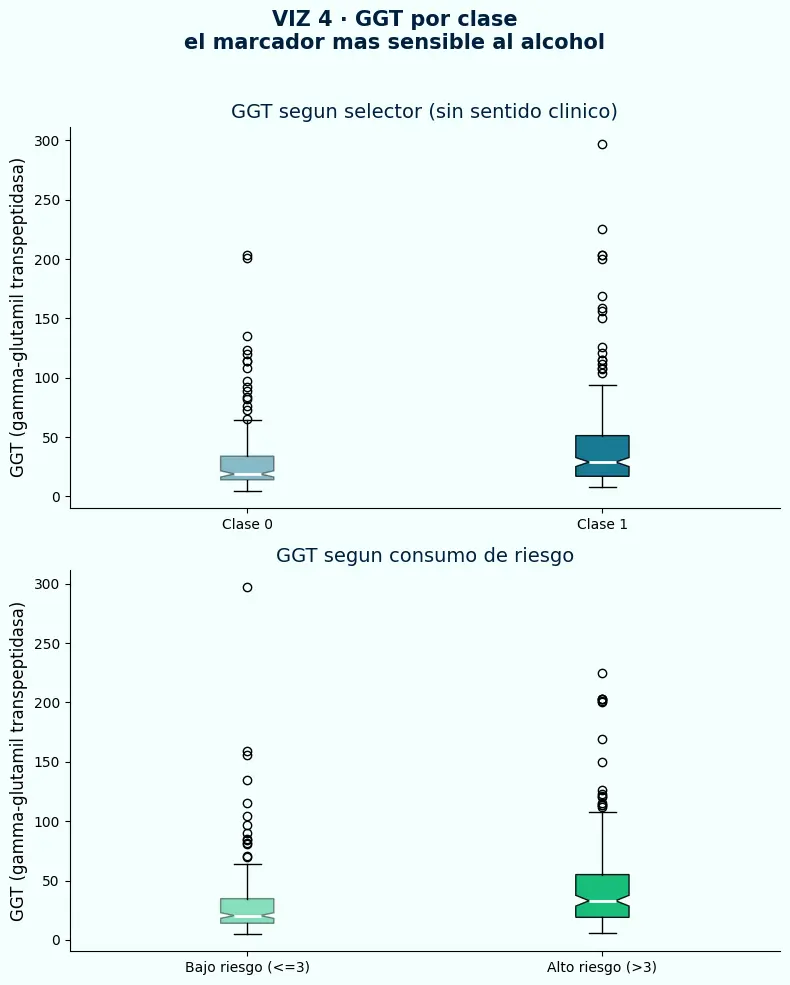
- Con el target incorrecto, las distribuciones de GGT entre clases se solapan casi completamente — el modelo no tiene señal real que aprender.
- Con el target correcto, el grupo de alto riesgo muestra medianas y dispersión claramente mayores — separación consistente con la literatura clínica.
- Cuando el modelo no puede separar grupos en la variable más discriminante del dominio, el target probablemente no responde ninguna pregunta real.
ResultadosQué cambia cuando defines bien el target
Mismo modelo, mismos datos, mismos features. La única variable entre experimentos es la definición del target.
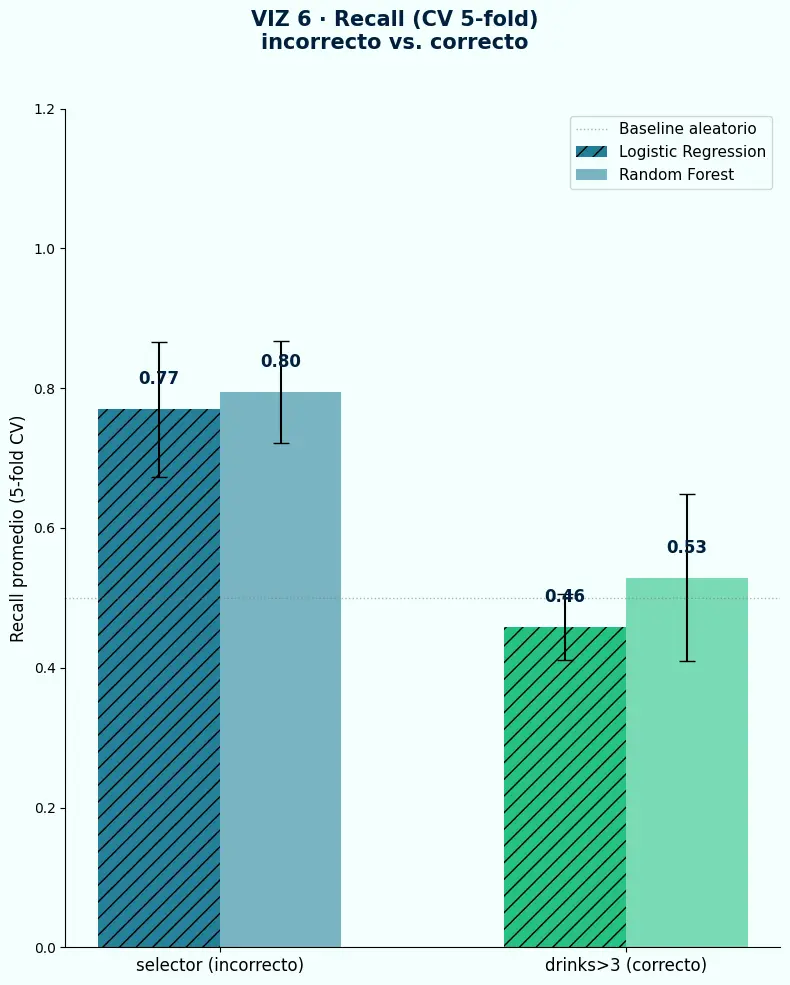
- El modelo con el target incorrecto obtiene Recall de 0.77 — un número que parece bueno y no significa nada, porque está aprendiendo a predecir un indicador train/test.
- El modelo con el target correcto obtiene Recall de 0.46 — más bajo, pero es la única cifra que mide algo real: detección de consumo de riesgo.
- Un Recall alto con un target mal definido es el resultado más peligroso que puede producir un experimento: da confianza falsa antes del despliegue.
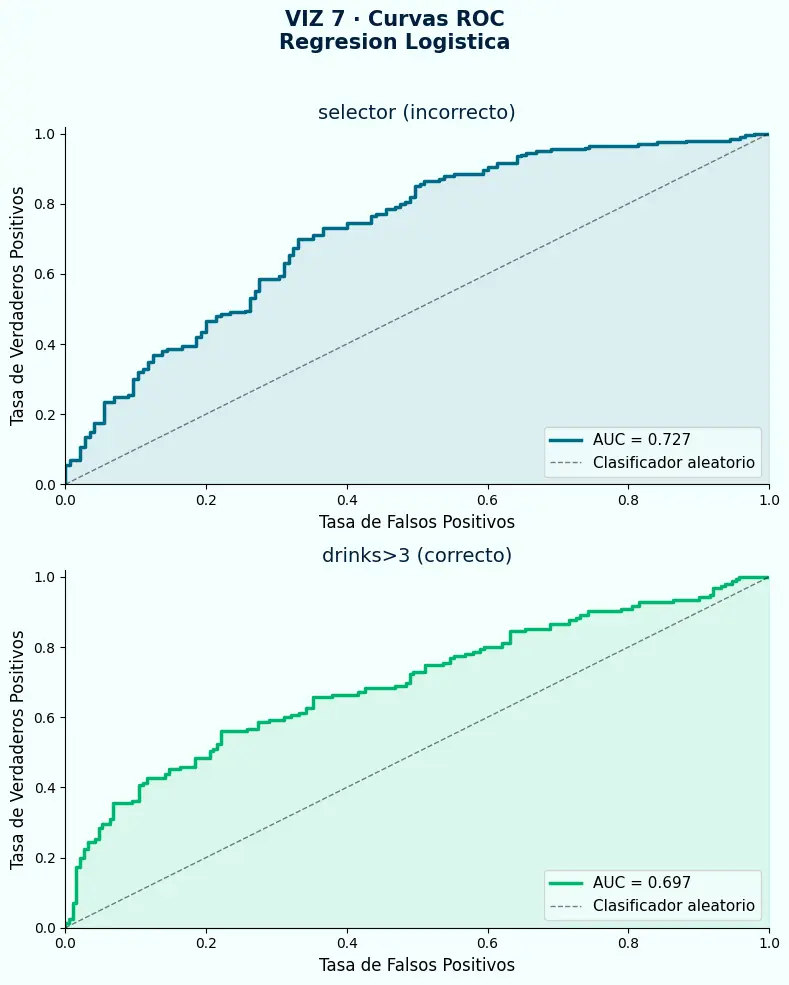
- AUC 0.727 con el target incorrecto vs. AUC 0.697 con el correcto — una diferencia pequeña que esconde una diferencia fundamental: uno discrimina ruido, el otro discrimina un fenómeno real.
- El modelo con
selectorcomo target tiene una curva ROC que parece competente. No hay ninguna señal visual de que algo está mal — ese es el problema. - Las métricas no detectan targets mal definidos. Solo lo hace quien lee la documentación de los datos antes de modelar.
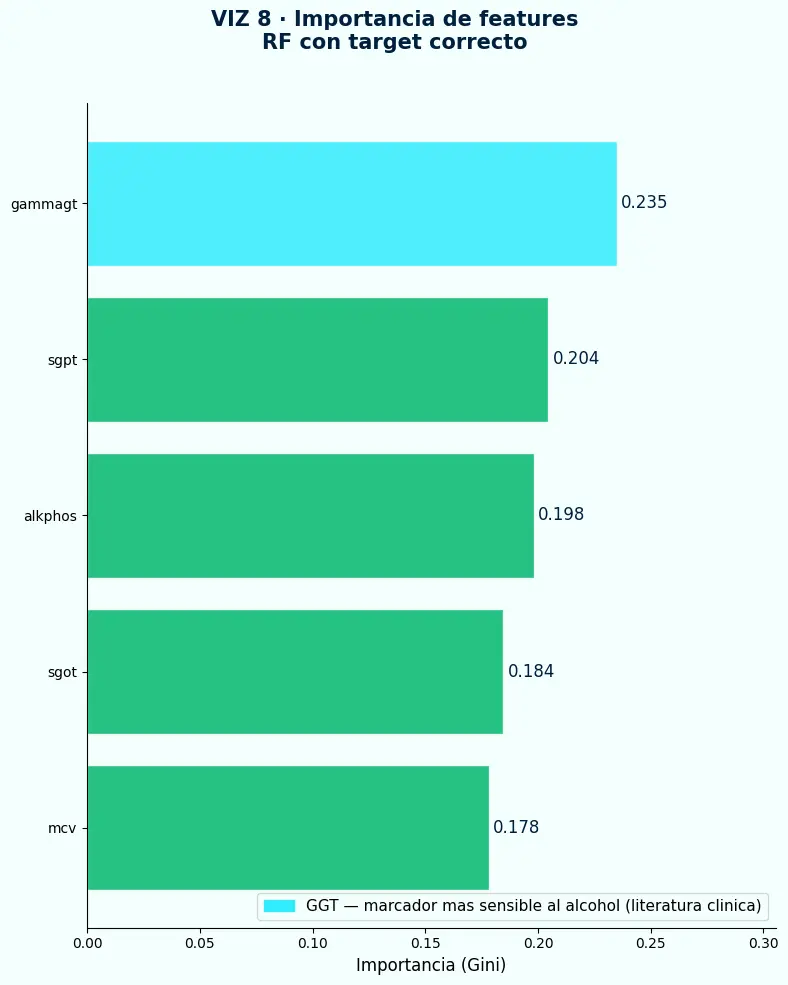
- GGT lidera con importancia 0.235 — el modelo llegó a esa conclusión solo, sin que nadie se lo indicara. La literatura clínica dice lo mismo.
- Cuando el feature más importante del modelo coincide con el marcador más relevante del dominio, es validación de que el target está bien definido.
- Si los features líderes no tienen sentido en el contexto del problema, revisar primero el target antes de cambiar el modelo.
CódigoRepositorio del experimento
El notebook completo incluye la construcción de ambos targets, el pipeline de validación cruzada y las 8 visualizaciones.
- Dataset: BUPA Liver Disorders — UCI ML Repository (ID: 60) — público, sin registro.
- Modelos: Regresión Logística y Random Forest, mismos hiperparámetros para ambos targets.
- Visualizaciones: distribución de clases, correlaciones, boxplots, heatmap, Recall comparativo, curvas ROC e importancia de features.