Cómo diseñar un proyecto completo de machine learning: Tips y buenas prácticas
Obtén una estructura clara para definir objetivos, datos, métricas y decisiones clave antes de la implementación.

¿Has pasado horas viendo tutoriales de machine learning y aun así no sabes cómo empezar tu propio proyecto?
Es una situación más común de lo que parece. Muchas personas aprenden modelos, herramientas y técnicas de IA, pero cuando intentan aplicarlas a un problema real descubren que no saben por dónde empezar.
Ahí es donde entra el diseño de proyectos de machine learning. Antes de elegir algoritmos o escribir código, necesitas una estructura clara que te ayude a definir objetivos, datos, métricas y restricciones.
Hecho correctamente, el diseño del proyecto puede ahorrarte semanas de trabajo, evitar errores costosos y ayudarte a construir una solución que realmente resuelva tu problema.
Puntos clave:
- Un proyecto de machine learning comienza mucho antes de elegir un algoritmo.
- Un buen diseño ayuda a convertir una idea en un proyecto claro y ejecutable.
- Los objetivos, datos y métricas deben definirse desde el inicio.
- Muchos bloqueos aparentemente técnicos son en realidad problemas de planificación.
- Invertir tiempo en el diseño puede ahorrarte tiempo, esfuerzo y frustración más adelante.
Después de asesorar más de 50 proyectos de machine learning, he encontrado una dificultad común. Muchas personas saben qué quieren resolver, pero no cómo diseñar el proyecto que les permita llegar a una solución.
No contar con una estructura clara para diseñar el proyecto dificulta transformar una idea en un plan de trabajo ejecutable.
Sin esa etapa de diseño, es fácil sentirse bloqueado, avanzar sin dirección o tener dificultades para entender por qué ciertas decisiones y resultados no funcionan como se esperaba.
Tabla de contenido:
- El diseño como fundamento de la ingeniería de machine learning
- El mapa de diseño. ¿Cómo transformar una idea en un proyecto de ML?
- Definir el problema. ¿Qué decisión quieres mejorar?
- Estrategia de datos. ¿Qué información necesitas para resolverlo?
- Elegir el tipo de modelo. ¿Qué enfoque se ajusta mejor al problema?
- Definir métricas de éxito. ¿Cómo sabrás que la solución funciona?
- Alcance y restricciones. ¿Qué hace viable el proyecto?
- Diseñar la operación. ¿Cómo funcionará el sistema en el mundo real?
- Ejemplos de proyectos. Cómo aplicar este enfoque paso a paso
- Caso especial: Tesis. ¿Qué cambia cuando tu proyecto es académico?
- Preguntas frecuentes
Termina ya tu proyecto
Ya tomaste cursos… pero no sabes cómo aplicarlo
El 92% de los profesionales de datos desbloquea sus proyectos al ver ejemplos completos resueltos.
Sin registro · Acceso inmediato
El diseño como fundamento de la ingeniería de machine learning
Si ya sabes hacer EDA, entrenar modelos y evaluar resultados, ¿por qué algunos proyectos siguen sintiéndose caóticos?
La razón es que los proyectos de machine learning no se construyen ejecutando tareas. Se construyen tomando decisiones.
Al terminar esta sección entenderás cuál es la diferencia entre aplicar técnicas de machine learning y diseñar proyectos de machine learning.
El error es pensar que un proyecto real puede resolverse siguiendo el mismo procedimiento que aparece en un tutorial.
Los tutoriales enseñan tareas técnicas. Los proyectos reales exigen tomar decisiones que cambian según el problema, los datos disponibles, las restricciones y el contexto.
Por eso muchas personas llegan a una situación frustrante: saben limpiar datos, hacer análisis exploratorio, entrenar modelos y calcular métricas, pero aun así no saben cómo empezar un proyecto propio o por qué su solución no termina de funcionar.
El proyecto real introduce preguntas que el tutorial nunca responde:
- ¿Qué problema vale la pena resolver?
- ¿Qué datos son realmente útiles?
- ¿Qué significa éxito en este contexto?
- ¿Qué limitaciones tiene la solución?
- ¿Cómo se utilizará una vez implementada?
Desarrollar proyectos de machine learning no consiste únicamente en entrenar modelos. Es una disciplina de ingeniería.
Esto no es solo una opinión.
En el paper Hidden Technical Debt in Machine Learning Systems, presentado por investigadores de Google en NeurIPS, se muestra que el código del modelo representa una pequeña parte de un sistema de machine learning en producción.
Mira la siguiente figura:
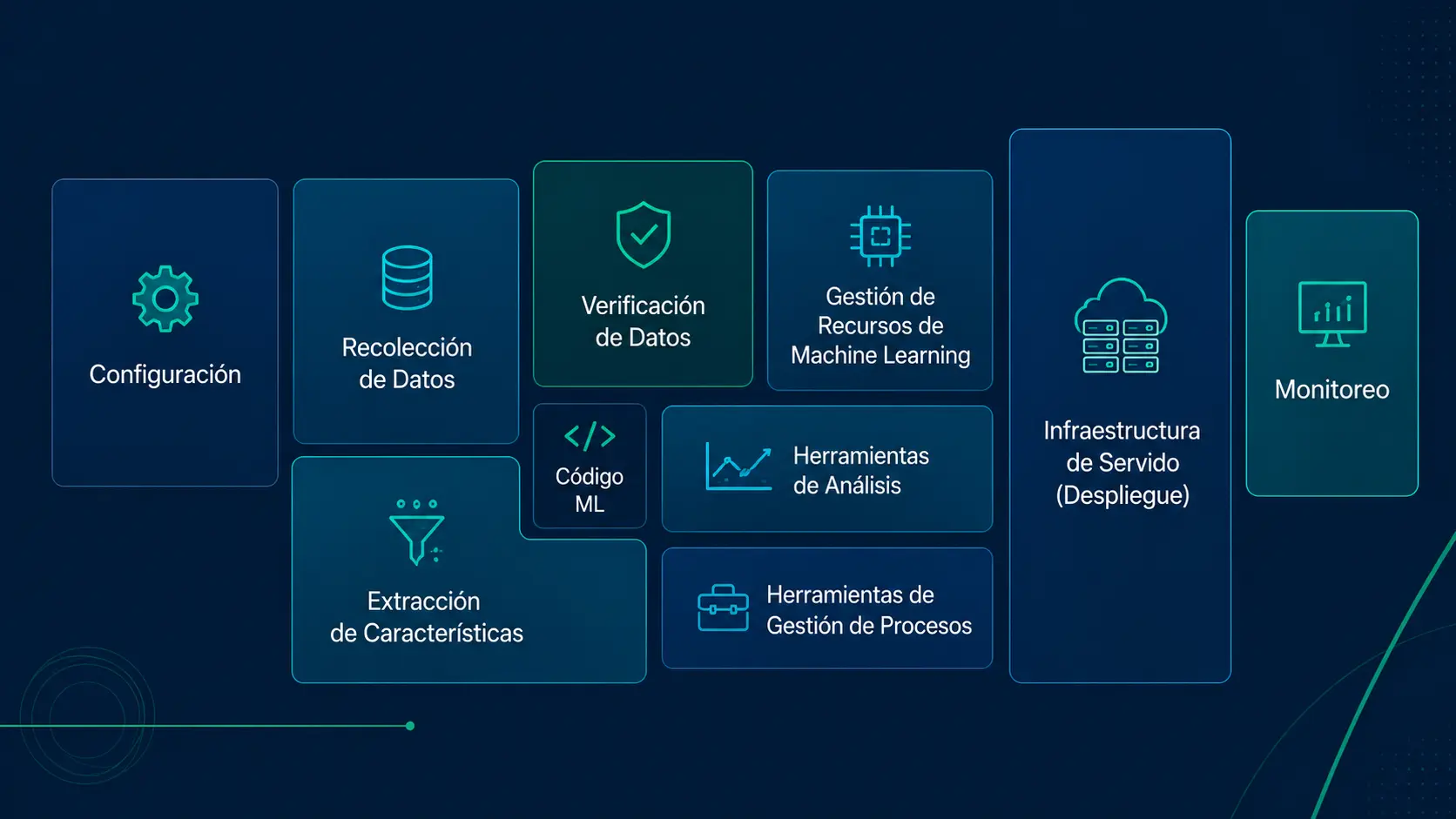
La mayor parte de la complejidad proviene de la infraestructura, los pipelines de datos, la integración con otros sistemas y las decisiones de diseño que se toman antes de escribir una sola línea de código.
Tantas variables involucradas requieren planificación. Y como cada proyecto tiene objetivos, datos y restricciones diferentes, esas decisiones no pueden resolverse siguiendo una receta única.
De forma similar las Rules of ML de Google, animan a pensar en términos de ingeniería y no únicamente en términos de modelado. El objetivo no es entrenar modelos cada vez más sofisticados, sino construir sistemas capaces de resolver problemas reales.
Dicho de otra forma: la diferencia entre alguien que sigue tutoriales y alguien que desarrolla proyectos no está en las herramientas que conoce, sino en las decisiones que sabe tomar.
Esta entrada del manual es una introducción a la Ingeniería de Machine Learning. Su propósito no es enseñarte un modelo específico, sino ayudarte a decidir qué herramientas, técnicas y enfoques tienen sentido según el problema que quieres resolver.
Para lograrlo, necesitamos pensar como ingenieros: entender el ciclo de vida de un sistema de machine learning y traducirlo en decisiones concretas de diseño.
Esas decisiones pueden organizarse en seis categorías que estructuran prácticamente cualquier proyecto de machine learning.
El mapa de diseño: las 6 decisiones que transforman una idea en un proyecto de machine learning
Los proyectos de machine learning no se construyen ejecutando tareas. Se construyen tomando decisiones.
La razón es que ninguna secuencia de pasos técnicos funciona para todos los proyectos. Puedes seguir exactamente el mismo tutorial que otra persona y aun así no saber cómo avanzar en tu propia idea.
De los tutoriales sabes cómo limpiar datos, hacer EDA, entrenar modelos y calcular métricas. Pero cuando intentas aplicar esas técnicas a una idea propia, aparecen preguntas que ningún tutorial puede responder por ti:
- ¿Mi idea realmente es viable?
- ¿Este modelo tiene sentido para mi problema?
- ¿Cómo sé si mi proyecto tendrá impacto?
- ¿Voy por buen camino o estoy perdiendo el tiempo?
No necesitas otro tutorial para responder las pregutnas anteriores. Necesitas un mapa de diseño.
Yo utilizo el siguiente mapa de diseño de proyectos de machine learning. No es una metodología rígida ni una receta de cocina. Es un marco para transformar una idea inicial en un proyecto con objetivos, criterios de éxito y una dirección clara.
Observa que el mapa está organizado alrededor de tres checkpoints. Cada uno reduce una parte de la incertidumbre que suele aparecer cuando intentas convertir una idea en un proyecto de machine learning.
Ya sabes si el proyecto es posible.
Ya sabes cómo demostrar contribución e impacto.
Ya tienes más claridad para materializar tu proyecto.
Checkpoint 1. ¿Mi proyecto es realmente posible?
Antes de pensar en modelos, necesitas saber si existe un problema claro y si dispones de los datos necesarios para resolverlo.
- Definir el problema. ¿Qué decisión quieres mejorar?
- Estrategia de datos. ¿Qué información necesitas para resolverlo?
Si llegas a este checkpoint, ya sabes si tu idea es viable.
Checkpoint 2. ¿Cómo demostraré contribución e impacto?
Una vez validada la idea, necesitas demostrar que vale la pena desarrollarla y definir bajo qué condiciones tendrá éxito.
- Definir métricas de éxito. ¿Cómo sabrás que la solución funciona?
- Alcance y restricciones. ¿Qué hace viable el proyecto?
Si llegas a este checkpoint, ya sabes cómo justificar el valor de tu proyecto.
Checkpoint 3. ¿Cómo convertiré la idea en una solución real?
Solo cuando las decisiones anteriores están claras tiene sentido elegir tecnologías y pensar en implementación.
- Elegir el tipo de modelo. ¿Qué enfoque se ajusta mejor al problema?
- Diseñar la operación. ¿Cómo funcionará el sistema en el mundo real?
Si llegas a este checkpoint, ya tienes claridad para materializar el proyecto.
En las siguientes secciones veremos cómo tomar cada una de estas decisiones de diseño.
Termina ya tu proyecto
Ya tomaste cursos… pero no sabes cómo aplicarlo
El 92% de los profesionales de datos desbloquea sus proyectos al ver ejemplos completos resueltos.
Sin registro · Acceso inmediato
Cómo definir el problema en tu proyecto de machine learning
Definir el problema en un proyecto de machine learning es una decisión técnica disfrazada de administrativa. Es el paso que más se omite y el que más proyectos destruye.
Para la definición del problema, este artículo de Google muestra que las pruebas que establezcamos para validar nuestro sistema son clave, pero ¿cómo las vas a establecer si antes no has definido el problema?
Por ejemplo, hace tiempo asesoré un proyecto relacionado con deserción estudiantil. Cuando recibí el proyecto, las métricas de clasificación eran prácticamente equivalentes a las de un clasificador aleatorio. Ya habían probado varios modelos y ninguno parecía funcionar.
En ese punto sugerí dar un paso atrás. Puede sentirse como perder tiempo, pero en este caso fue lo que salvó el proyecto.
Lo primero que pregunté fue:
- ¿Puedes definir claramente el resultado que quieres predecir?
- ¿Ese resultado impacta una métrica de negocio concreta?
La respuesta reveló el problema.
El modelo estaba intentando predecir si un alumno estaba inscrito o no en un período determinado. Pero ese target ignoraba completamente el tiempo. No comparaba el estado del alumno entre períodos consecutivos.
Y ahí estaba el error.
La deserción no es un estado, es un cambio.
No importa si un alumno no está inscrito hoy; importa si dejó de estarlo respecto al período anterior.
Por ejemplo: si un alumno aparece como "no inscrito" en dos períodos consecutivos, el modelo lo trataba como si no hubiera desertado. Pero en realidad, ese alumno pudo haber desertado antes. El modelo no tenía forma de saberlo porque el target no capturaba la transición.
En otras palabras, el problema no era el modelo. Era la definición del target.
Lo resolvimos redefiniendo la variable objetivo usando información temporal: en lugar de predecir estado, pasamos a modelar el cambio entre períodos. Esto implicó ingeniería de características y reconstrucción del target a partir de secuencias de inscripción.
Con ese ajuste, y usando los mismos datos, el modelo mejoró sus métricas en más de un 30%.
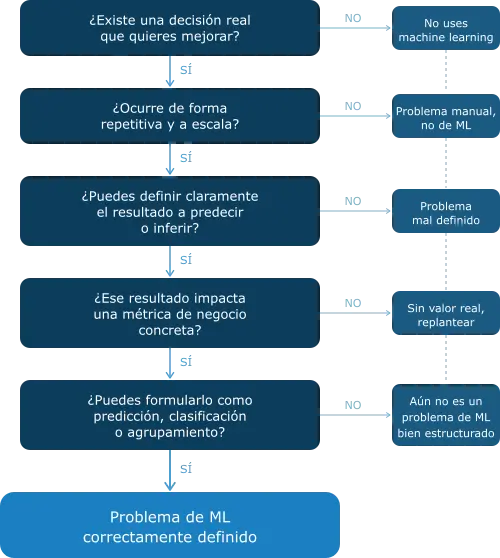
Lo que fallaba no era el modelo. Era la definición del problema.
Este es exactamente el tipo de error que un flowchart de diseño busca evitar: intentar modelar algo que aún no está bien formulado. Hasta que no definimos la deserción como un cambio entre períodos, no existía un problema de machine learning claro.
Una vez hecho ese ajuste, el problema se convierte naturalmente en una tarea de clasificación. Y solo en ese punto tiene sentido hablar de modelos.
Con el problema bien definido, ahora sí podemos pasar a la siguiente decisión de diseño: la selección del tipo de modelo.
Dónde conseguir datos para tu proyecto de IA antes de construir el modelo
Cómo empezar en machine learning depende casi siempre de una pregunta que ningún curso responde: ¿de dónde van a salir los datos reales cuando salgas del dataset de práctica?
Cuando trabajas con problemas reales, los datos casi nunca están listos para entrenar.
De hecho, muchas veces ni siquiera están estructurados. Te encuentras con PDFs, archivos de Excel y, en el mejor de los casos, una base de datos más o menos organizada.
Y eso no es un problema menor. Es una decisión de diseño.
Porque antes de programar necesitas entender de dónde vienen los datos, quién los genera, con qué frecuencia se actualizan y qué pasa cuando llegan incompletos o con errores.
Esto implica trabajo de ingeniería: definir diccionarios de datos, entender las relaciones entre variables y diseñar estructuras que tengan sentido para el problema que quieres resolver.
En un proyecto que desarrollé, trabajábamos con reportes operativos que no estaban pensados para análisis. Tuvimos que rediseñar completamente la estructura de los datos para poder reconstruir la información de forma consistente. No fue solo limpiar datos, fue diseñar cómo debían existir.
Y eso cambió todo el sistema.
Porque los datos no son una entrada técnica. Son parte del diseño del sistema de machine learning.
Ahora bien, también hay escenarios donde simplemente no tienes los datos. En esos casos, necesitas saber dónde buscarlos. Aquí tienes algunas fuentes útiles según el tipo de proyecto:
| Tipo de proyecto | Fuente recomendada | Liga |
|---|---|---|
| Finanzas | World Bank Open Data | data.worldbank.org |
| IMF Data | imf.org/en/Data | |
| Retail / e-commerce | Google Analytics (datos propios) | analytics.google.com |
| Kaggle | kaggle.com/datasets | |
| Salud | WHO | who.int/data |
| CDC | data.cdc.gov | |
| Ciencias sociales | INEGI | inegi.org.mx/datos |
| Data.gov | data.gov | |
| NLP / texto | Hugging Face | huggingface.co/datasets |
| Common Crawl | commoncrawl.org | |
| Visión por computadora | ImageNet | image-net.org |
| Roboflow | universe.roboflow.com |
Cómo elegir el tipo de modelo sin escribir una línea de código
Antes de empezar a entrenar modelos, la estructura de tu problema ya te dice qué tipo de modelo necesitas.
Regresando al ejemplo de deserción estudiantil, una vez definido el problema, el siguiente paso fue elegir el tipo de modelo.
En este caso, el problema quedó formulado como clasificación. Queríamos predecir si un alumno iba a desertar o no. Eso ya limita mucho el tipo de modelos que tiene sentido usar.
También teníamos etiquetas disponibles, lo cual hacía viable este enfoque desde el inicio.
Pero lo más importante no fue eso.
El modelo tenía que integrarse con cómo la universidad ya trabajaba. Ellos operaban con Excel. No iban a montar una infraestructura compleja ni a usar herramientas nuevas.
Por eso optamos por uno simple, pequeño y fácil de interpretar. Era la primera vez que implementaban algo así, así que la claridad importaba más que la sofisticación.
Y funcionó.
Esta decisión de diseño además está alineada a las Reglas de ML de Google sobre empezar simple, sobre todo cuando apenas se está adoptando este tipo de sistemas.
Este es un patrón que se repite mucho en proyectos reales. El tipo de modelo no lo define el rendimiento máximo posible, lo definen las restricciones del negocio.
Antes de abrir un notebook, hay una pregunta que todo equipo debería responder:
¿Qué tipo de modelo tiene sentido en el sistema que realmente vas a construir?
En este punto ya tenemos el problema definido y el tipo de modelo claro. Ahora viene la pregunta clave: ¿cómo sabemos si realmente funciona?
Cómo definir métricas de éxito antes de entrenar tu modelo
Otro error de diseño común en un proyecto de machine learning no es elegir el algoritmo incorrecto. Es empezar a entrenar sin haber definido qué significa que el modelo funciona.
Para explicarlo, aquí va otra anécdota. Trabajando con una empresa de finanzas, la discusión no fue el modelo. Fue cómo definir si realmente estaba funcionando.
Y eso empieza antes de entrenar.
Primero tuvimos que entender el negocio. El objetivo no era solo predecir, era separar correctamente a los clientes según su nivel de riesgo. Por ejemplo, cómo se distribuía el riesgo en percentiles o qué tan bien distinguíamos entre buenos y malos pagadores.
A partir de ahí, definimos las métricas de negocio.
Luego vino la pregunta clave: ¿qué métrica de machine learning representa mejor eso? En algunos casos, métricas como AUC o accuracy podían servir como aproximación, pero solo si reflejaban correctamente esa separación de riesgo que el negocio necesitaba.
Después definimos el umbral. No basta con que el modelo sea "bueno", tiene que superar un nivel mínimo que lo haga útil en la operación.
Este proceso se repitió con otras métricas. Cada una tenía que tener sentido tanto desde el modelo como desde el negocio.
Porque aquí está el punto importante.
No todas las métricas que optimizas en machine learning son las que realmente importan en producción. Algunas deben cumplirse en el modelo, pero otras viven directamente en el sistema de negocio.
Cuando alineas ambas, el modelo deja de ser un experimento y se convierte en una herramienta útil.
Cómo definir el alcance y las restricciones del sistema antes de programar
El alcance no es una lista de features. Es lo que define qué entra al sistema, qué sale y qué pasa cuando el modelo no sabe.
Y eso está determinado por restricciones.
Antes de programar, hay al menos cuatro que necesitas tener claras:
- La latencia aceptable
- El volumen de datos en producción
- La frecuencia con la que el modelo se va a actualizar
- Las condiciones de privacidad
Estas no son decisiones técnicas de último momento. Son decisiones de diseño que cambian completamente el tipo de sistema que puedes construir.
En mi caso, esto fue muy claro en un proyecto de tesis donde teníamos que generar mapas de navegación para robots.
Podíamos usar mapas complejos, incluso representaciones en 3D. Pero había una restricción clave: el mapa tenía que vivir dentro del robot.
Eso implicaba memoria limitada, baja latencia y la necesidad de calcular todo fuera de línea.
Esa sola decisión cambió todo.
Terminamos usando metaheurísticas. Algunos las consideran parte de machine learning, otros no. Pero lo importante no es la etiqueta, es que cumplían con las restricciones del sistema.
El mapa tenía que ser ligero, rápido de consultar y lo suficientemente compacto para ejecutarse en el hardware disponible.
Aquí el modelo no fue el punto de partida. Fue una consecuencia de las restricciones.
Esto pasa constantemente en proyectos reales. No diseñas el modelo y luego ves cómo lo usas. Diseñas el sistema, y eso define qué modelo es posible.
Y hay una pregunta que resume todo esto:
¿Este sistema necesita responder en tiempo real o puede funcionar en batch?
Cómo llevar un sistema de machine learning a producción y hacerlo funcionar en la práctica
Llevar un sistema de machine learning a producción no es solo un problema técnico. Es un problema de adopción.
En muchos casos, la forma en que implementas el sistema depende más de la madurez de la organización que del modelo en sí. No es lo mismo integrar un modelo en una empresa que ya trabaja con datos, que en una donde apenas se están dando los primeros pasos.
Por ejemplo, en algunos proyectos hemos optado por soluciones simples, como exponer el modelo a través de un servicio que puede ser consumido directamente desde Excel. Esto reduce la fricción y facilita la adopción, porque no obliga a los usuarios a cambiar la forma en la que ya trabajan.
En otros casos, cuando buscamos mayor control o aprendizaje, hemos implementado aplicaciones independientes, desplegadas en la nube o en servidores internos. Esto permite aislar el sistema del flujo operativo y entender mejor cómo debe integrarse en el proceso.
Y aquí es donde aparece un punto clave: el éxito de un sistema no depende solo de la tecnología.
Depende de tres cosas:
- Las personas
- Los procesos
- Y la tecnología
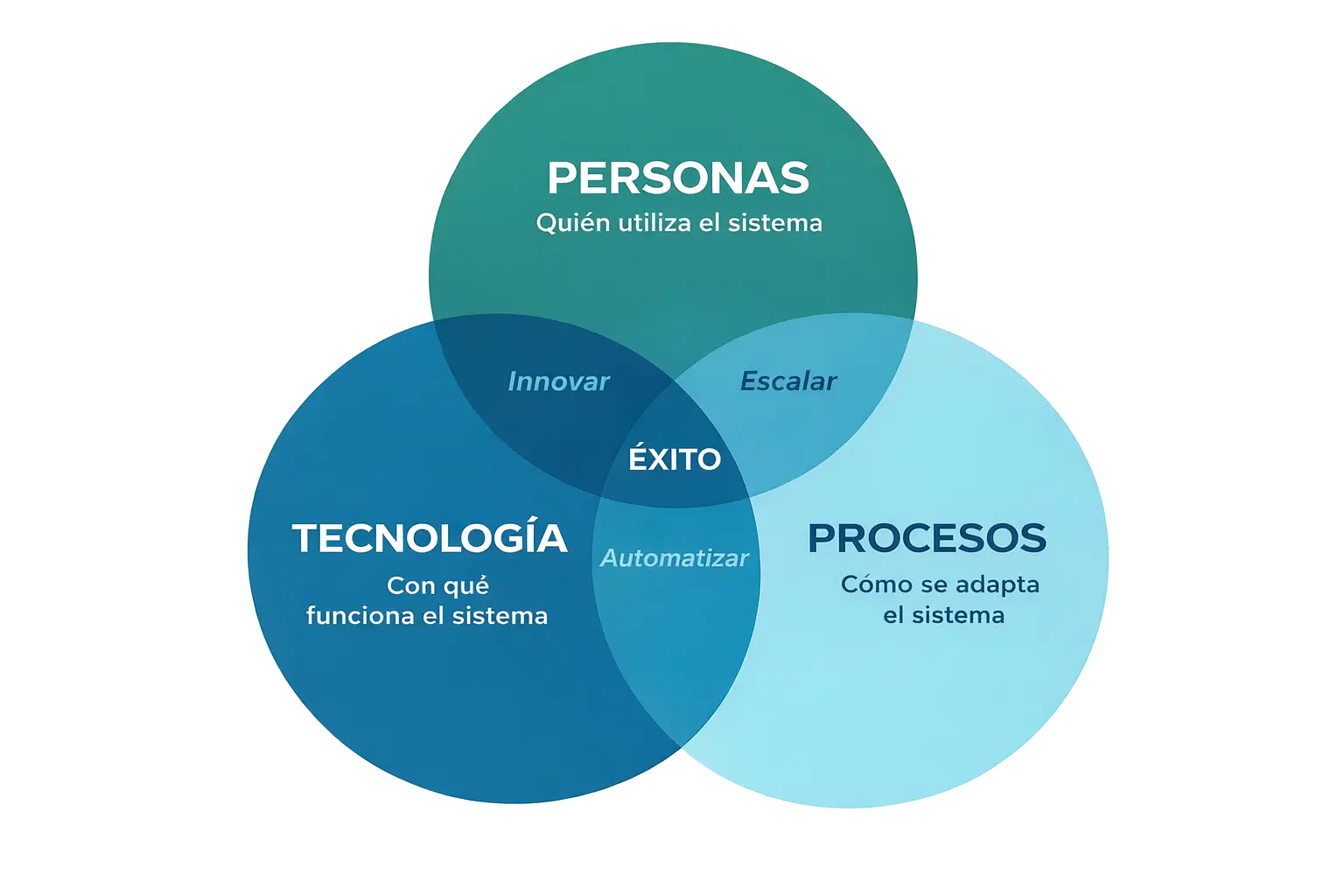
Si las personas no entienden el sistema, no lo usan. Si los procesos no se adaptan, el sistema estorba. Y si la tecnología no encaja, simplemente no escala.
Esto es algo que se repite constantemente. Hemos visto modelos técnicamente sólidos que fallan porque nadie los usa, y otros más simples que generan impacto real porque se integran bien en el flujo de trabajo.
Hay también casos donde la adopción es más natural. Por ejemplo, en sistemas de visión por computadora, donde el modelo puede integrarse de forma más automática en el proceso, la fricción suele ser menor.
Pero incluso ahí, el principio es el mismo: no diseñas el modelo para después ver cómo usarlo. Diseñas el sistema completo, incluyendo cómo se va a usar en la práctica.
Porque al final, un modelo en producción no es solo código funcionando. Es un sistema que alguien tiene que usar.
Cómo se ve este enfoque aplicado en proyectos reales
Agricultura — Predicción de precios y optimización nutricional
Problema: estimar precios de abarrotes y optimizar combinaciones alimenticias de menor costo. (FuzzyFrog.AI)
Antes de programar, se tomaron tres decisiones clave. Primero, definir el problema como dos capas: predicción de precios (regresión) y optimización bajo restricciones. Segundo, estructurar los datos como series de tiempo locales, priorizando disponibilidad real sobre complejidad. Tercero, elegir modelos interpretables que permitieran explicar resultados a usuarios no técnicos.
Resultado: un sistema que no solo predice precios, sino que permite tomar decisiones prácticas sobre alimentación y costo en contextos reales.
Industria — Predicción de resistencia del cemento
Problema: estimar la resistencia del cemento en función de su composición y condiciones de fraguado. (FuzzyFrog.AI)
Antes de programar, se tomaron tres decisiones clave. Primero, formular el problema como regresión continua desde el diseño, no como clasificación simplificada. Segundo, definir las variables relevantes desde la física del material, no solo desde correlaciones. Tercero, priorizar estabilidad y generalización del modelo sobre rendimiento máximo en entrenamiento.
Resultado: un modelo capaz de predecir resistencia en distintos escenarios de producción, útil para control de calidad y toma de decisiones en planta.
Preguntas frecuentes sobre proyectos de machine learning desde cero
¿Cuál es el primer paso para hacer un proyecto de IA desde cero?
El primer paso para hacer un proyecto de IA desde cero es definir correctamente el problema. Debes entender qué quieres predecir y qué decisión de negocio depende de esa predicción.
¿Cómo sé qué tipo de modelo de machine learning necesito para mi problema?
Para saber qué tipo de modelo de machine learning necesitas, primero debes estructurar el problema. Si es predicción, clasificación o agrupamiento, el tipo de modelo se define antes de programar.
¿Qué datos necesito antes de empezar un proyecto de inteligencia artificial?
En un proyecto de inteligencia artificial necesitas datos que reflejen el problema real. Debes definir su origen, estructura, frecuencia de actualización y qué hacer si llegan incompletos o incorrectos.
¿Cuándo no debo usar machine learning para resolver un problema?
No debes usar machine learning cuando el problema no está bien definido o no impacta una decisión real. Si no puedes formularlo claramente, el modelo no aportará valor.
¿Cuál es la diferencia entre diseñar y construir un sistema de machine learning?
La diferencia entre diseñar y construir un sistema de machine learning es que diseñar define decisiones clave como problema, datos y métricas, mientras construir es implementar modelos bajo esas decisiones.
Si tu proyecto de machine learning es para una tesis, empieza aquí
Aplicar machine learning en una tesis tiene restricciones que los tutoriales industriales no contemplan.
Tienes tiempo limitado, datos que no siempre son ideales y un comité que no solo quiere resultados; quiere entender por qué tomaste cada decisión.
Eso cambia completamente cómo diseñas el proyecto.
El alcance suele ser más estrecho. No necesitas resolver todo el problema, necesitas definir bien tu contribución: qué estás aportando y por qué eso es válido.
También cambia cómo eliges el modelo. En un entorno académico, no basta con que funcione. Tienes que justificar metodológicamente por qué elegiste ese enfoque y no otro.
Y lo mismo pasa con las métricas. Aquí no solo importa el impacto en negocio, importa la validez del resultado desde un punto de vista técnico y académico.
Muchos piensan que, como es una tesis, el riesgo es menor.
Pero no es así.
Si el proyecto no está bien definido, te atrasas. Y atrasarte significa pagar otro semestre, otro ciclo. Termina siendo un costo real.
Por eso es clave que desde el inicio tengas claro qué problema estás resolviendo, cuál es tu alcance y cómo vas a demostrar que tu solución funciona.
Si estás en ese punto y quieres una guía más clara, puedes ver cómo estructurar tu proyecto paso a paso en la guía completa sobre cómo usar machine learning en tu tesis.
Y si ya tienes un proyecto en marcha, ya sea académico o aplicado, y necesitas ayuda para definirlo o destrabarlo, puedes escribirme directamente. Muchas veces un ajuste en el diseño cambia todo el resultado.
Termina ya tu proyecto
Ya tomaste cursos… pero no sabes cómo aplicarlo
El 92% de los profesionales de datos desbloquea sus proyectos al ver ejemplos completos resueltos.
Sin registro · Acceso inmediato