/ Mini-Labs / Por qué mi modelo no mejora después de usar SMOTE
Por qué mi modelo no mejora después de usar SMOTE
SMOTE promete resolver el desbalance de clases. A veces lo hace. A veces no cambia nada. A veces empeora las métricas que importan. Este experimento diagnostica por qué.
ContextoEl Recall de 0.74 que no vino de donde creías
SMOTE es una de las técnicas más aplicadas en clasificación desbalanceada — y una de las más malentendidas. No porque no funcione, sino porque los data scientists rara vez diagnostican por qué no están viendo el resultado esperado antes de descartarla.
- El modelo sin SMOTE tiene Recall = 0.123. Con SMOTE llega a 0.742. Eso es una mejora real — pero Precision cayó de 0.610 a 0.394 y nadie lo esperaba.
- Si estabas midiendo Accuracy o Precision, el resultado parece un deterioro. SMOTE no falló: la métrica objetivo estaba mal elegida desde el inicio.
- La curva Precision-Recall de ambos modelos es prácticamente idéntica — AP = 0.559 sin SMOTE, AP = 0.556 con SMOTE. SMOTE no amplió la capacidad discriminativa del modelo. Solo movió el threshold.
- El data leakage infla los resultados de CV: aplicar SMOTE antes de la validación cruzada produce Recall = 0.775 frente al 0.742 real. La diferencia llega a producción.
- El solapamiento de clases en PCA es la señal más temprana: si las clases se mezclan en dos componentes, ninguna técnica de rebalanceo va a resolver el problema. El problema está en los features.
- Diagnosticar cuál de estas cuatro causas aplica no requiere más datos ni un algoritmo distinto — requiere ejecutar las visualizaciones correctas antes de aplicar SMOTE.
DatosVer el desbalance antes de decidir cómo corregirlo
El dataset Blood Transfusion Service Center (UCI) tiene 748 registros de donantes con un ratio de clases de 3:1. Es el rango donde SMOTE se aplica con mayor frecuencia — y donde sus efectos secundarios son más fáciles de observar.
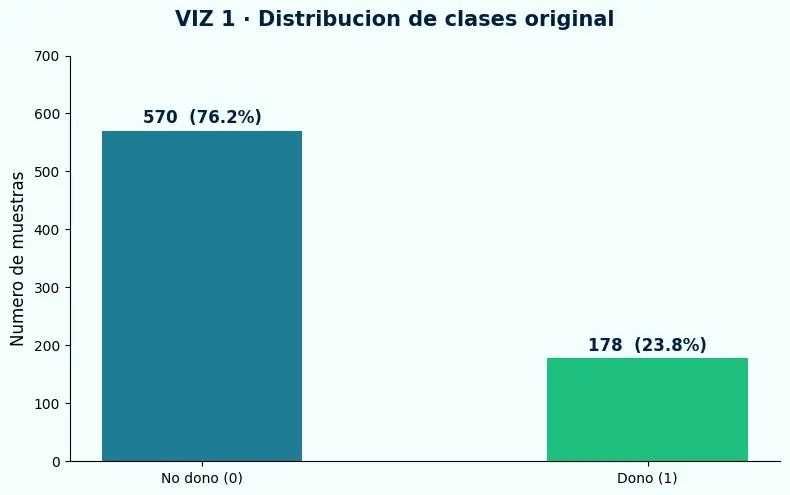
- El ratio de 3:1 es moderado — no crítico. Un modelo que falla con este desbalance rara vez lo hace por falta de muestras de la clase minoritaria.
- Antes de aplicar cualquier técnica de rebalanceo, la pregunta correcta es: ¿el desbalance es realmente la causa del problema, o hay algo más profundo?
- Un desbalance de 3:1 con clases bien separadas en el espacio de features no necesita SMOTE. Un desbalance de 3:1 con clases solapadas no se resuelve con SMOTE.
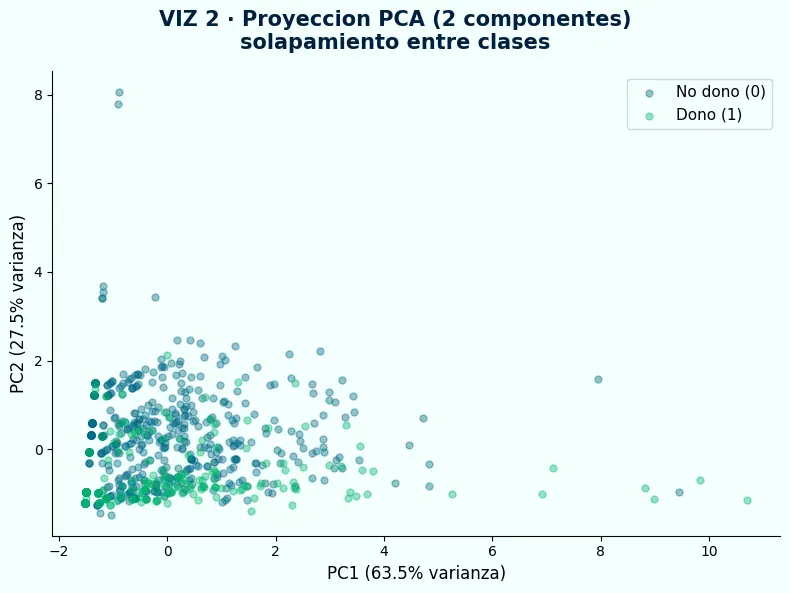
- PC1 explica el 63.5% de la varianza y PC2 el 27.5% — dos componentes capturan el 91% de la información del dataset. Lo que se ve en esta proyección es representativo.
- Las clases se mezclan completamente. No hay región del espacio donde una clase domine de forma clara. El problema es separabilidad, no conteo.
- SMOTE genera muestras sintéticas interpolando entre vecinos de la clase minoritaria. Si esos vecinos están rodeados de la clase mayoritaria, las muestras nuevas caen exactamente en la zona de mayor confusión.
DiagnósticoLas cuatro razones por las que SMOTE no funciona como se espera
SMOTE falla — o parece fallar — por razones distintas. Cada una tiene una señal visual diferente. Identificar cuál aplica en tu caso determina si la solución es corregir el pipeline, cambiar la métrica, ajustar el threshold o repensar los features.
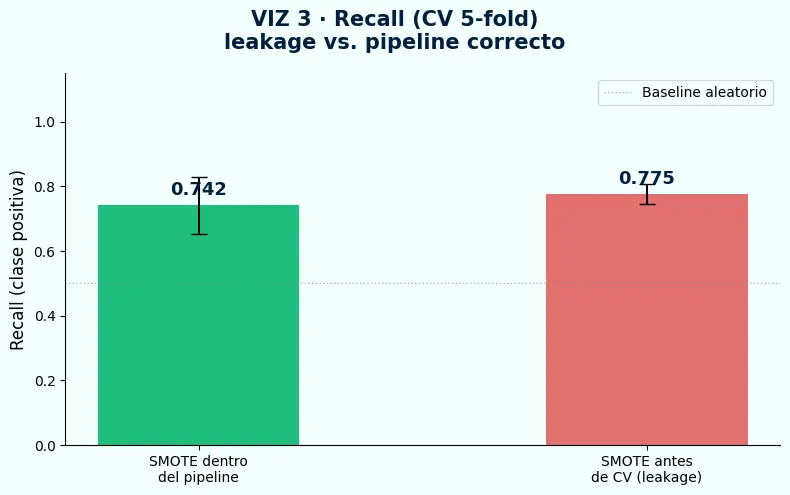
- SMOTE dentro del pipeline produce Recall = 0.742. SMOTE antes de CV produce Recall = 0.775. La diferencia parece pequeña — no lo es.
- Cuando SMOTE se aplica fuera del pipeline, las muestras sintéticas generadas a partir del set de entrenamiento contaminan el set de validación. El modelo evalúa sobre datos que derivaron de sus propios datos de entrenamiento.
- El modelo que llega a producción es el construido con datos contaminados. En producción no hay muestras sintéticas. Las métricas colapsan y nadie entiende por qué.
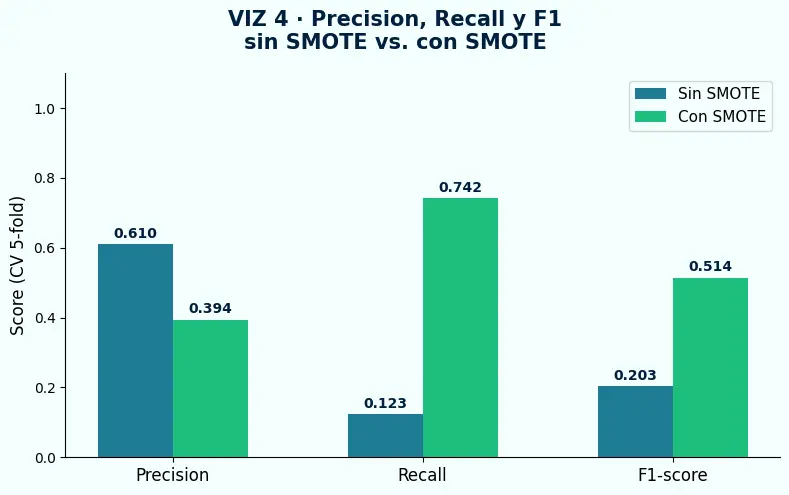
- Sin SMOTE: Recall = 0.123. Con SMOTE: Recall = 0.742. SMOTE hizo exactamente lo que prometía.
- Sin embargo, Precision cayó de 0.610 a 0.394. SMOTE mueve el tradeoff: el modelo predice positivo con más frecuencia, incluyendo más falsos positivos.
- Si la métrica que se monitorea es Precision o Accuracy, el resultado parece un deterioro. La pregunta que debe responderse antes de aplicar SMOTE: ¿qué es más costoso en este problema — un falso negativo o un falso positivo?
ModeloSMOTE no amplía la capacidad del modelo — solo mueve el threshold
La prueba más contundente de cuándo SMOTE no es la respuesta no viene de las métricas puntuales — viene de la curva Precision-Recall completa. Si ambas curvas son idénticas, SMOTE no aportó información nueva.
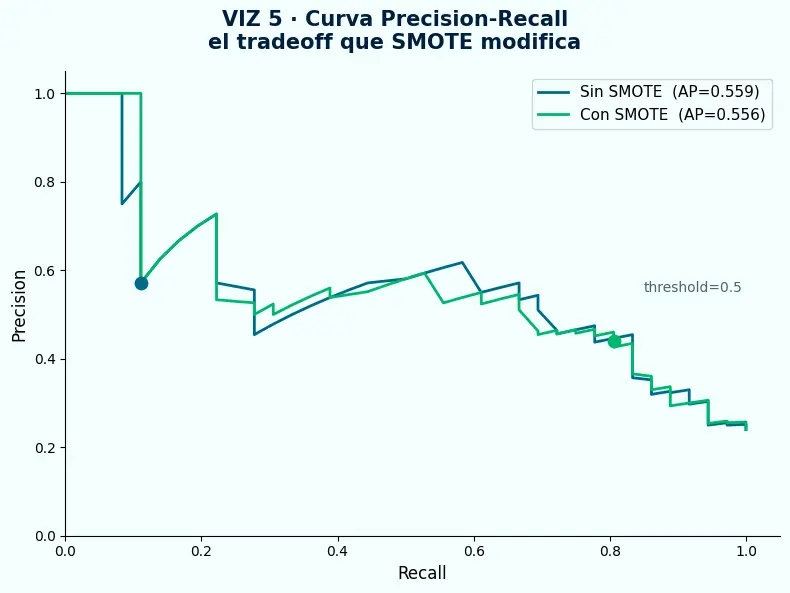
- AP sin SMOTE = 0.559. AP con SMOTE = 0.556. Las curvas son prácticamente la misma línea. Ambos modelos tienen exactamente la misma capacidad discriminativa.
- Lo que SMOTE hizo fue desplazar el punto de operación sobre esa curva: sin SMOTE el modelo opera con Precision alta y Recall bajo (punto azul, threshold = 0.5); con SMOTE opera con más Recall y menos Precision (punto verde).
- Ese mismo desplazamiento se puede lograr ajustando el threshold directamente sobre el modelo sin SMOTE — sin generar ninguna muestra sintética, con menos complejidad y con el mismo resultado en producción.
ResultadosQué responde cada visualización
Cada visualización de este experimento responde una pregunta diferente del diagnóstico. Juntas construyen el mapa completo de por qué SMOTE no produjo el resultado esperado.
- VIZ 1 — El desbalance es de 3:1. No es crítico. Si el modelo falla, la causa no es la cantidad de muestras.
- VIZ 2 — Las clases se solapan completamente en PCA. Más muestras sintéticas en la zona de confusión no reducen la confusión. El problema está en los features.
- VIZ 3 — SMOTE fuera del pipeline infla el Recall en 0.033 puntos. Ese modelo llega a producción y falla. La solución es de una línea:
ImbPipeline. - VIZ 4 — SMOTE funcionó. Recall subió de 0.123 a 0.742. Pero Precision bajó de 0.610 a 0.394. Si la métrica objetivo no estaba definida antes, cualquier resultado parece un fracaso.
- VIZ 5 — AP = 0.559 sin SMOTE, AP = 0.556 con SMOTE. Las curvas son idénticas. SMOTE no amplió la capacidad del modelo. Solo movió el threshold. Eso se puede hacer directamente, sin SMOTE.
CódigoRepositorio del experimento
El notebook completo incluye la carga del dataset desde UCI con fallback automático, el pipeline de diagnóstico, la comparación de las cuatro causas y las cinco visualizaciones.
- Dataset: Blood Transfusion Service Center — UCI ML Repository — público, sin registro. 748 registros de donantes del banco de sangre de Taiwan, variables RFM de donación y target binario.
- Causa 1 — Solapamiento: proyección PCA de dos componentes antes de aplicar SMOTE. Si las clases se mezclan, el problema es separabilidad, no conteo.
- Causa 2 — Leakage: comparación de Recall CV entre SMOTE dentro del pipeline (
ImbPipeline) y SMOTE aplicado antes decross_val_score. - Causa 3 — Tradeoff de métricas: Precision, Recall y F1 en CV 5-fold para el modelo sin SMOTE y con SMOTE aplicado correctamente.
- Causa 4 — Threshold: curva Precision-Recall completa con Average Precision para ambos modelos, con los puntos de operación en threshold = 0.5 marcados explícitamente.
- Modelo base: Regresión Logística con
StandardScaler, CV 5-fold estratificado,random_state=42en todos los pasos.