How to Design a Machine Learning Project from Scratch Before You Start Coding
A machine learning project is not just a model: it is a system. And that system is designed before writing any code.
Knowing how to build an AI project does not start by choosing an algorithm. It starts by making decisions about how the system should work in the real world.
In practice, a machine learning "project" is not just a Colab notebook generated by Claude; it is a complete system.
Designing a machine learning project means making decisions about the problem, the data, the model, the metrics, the constraints and the way the system operates in production.
These design decisions start with questions like:
- What problem are you solving and what decision does it impact?
- Where does the data come from and how is it maintained?
- What type of model does the problem require?
- Which metric defines success and at what threshold?
- What constraints condition the system?
- How is it deployed and maintained in production?
This applies equally whether you are developing a thesis or building a business system. In both cases, the result depends on something fundamental: making clear decisions based on the questions that guide the system design.
After building and advising more than 50 projects in sectors such as mining, retail and social sciences, I have seen a pattern:
- Teams that design the system before coding reach production.
- Students who design their project to identify their contribution, scope and limitations pass the course.
Table of contents:
- Why design really matters. What the experts say.
- The 6 key elements. Overview
- Define the problem. What happens if you model the wrong question?
- Data strategy. Where data comes from in real projects
- Choose the model type. Save time before writing code
- Define success metrics. How do you know the system actually works?
- Scope and constraints. What makes the system viable (or impossible)
- Taking to production. Adoption and operation of the system
- How this approach looks applied to real projects
- Frequently asked questions
- Special case: thesis. What changes when your project is academic
Why designing an AI project matters more than choosing the model
Most people looking for how to get started in machine learning go straight to the algorithms. The problem is that the algorithm is the last decision you should make; not the first.
This is not just an opinion. In the paper Hidden Technical Debt in Machine Learning Systems presented at Google NeurIPS, it is stated that only 5% of a Machine Learning system in production is model code; while the remaining 95% is infrastructure, data pipelines and design decisions made before opening a code editor.
Similarly, Google, in its ML Rules, urges us to do engineering when designing projects, not just training models.
In other words: you need to learn design criteria and not just AI models to create machine learning that helps you pass your course, or that is useful for your work.
That is why starting with the model is usually a mistake. This is something I have seen repeated in my own and advised projects:
Those who choose a model from day one without having thought through the system design end up working twice as hard or redoing the entire project.
This manual entry is an introduction to Machine Learning Engineering, and explains how to decide which tools, techniques and models to use based on the problem you have.
To achieve this, we need to think in engineering terms: understand the Machine Learning production cycle, and translate it into concrete design decisions.
Those decisions can be organized into six categories that structure the system.
Shall we begin?
The 6 elements you must design before coding your machine learning project
Starting an AI project from scratch without defining these six design elements is the reason why many projects stay in a notebook instead of reaching production or supporting a thesis.
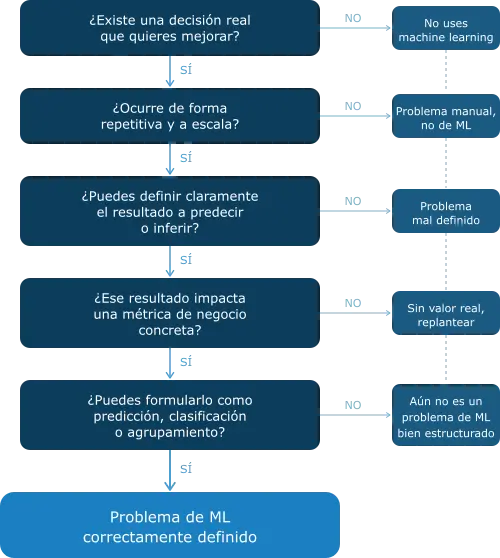
1. Problem definition
Design criterion: before choosing an algorithm you need to know exactly what question you want the model to answer and what business decision that answer will inform. Without this, any model is an answer to the wrong question. The problem definition determines the type of data you need, the metric you will use and the success criterion for the complete system.
You can see how to do it step by step in the problem definition section or in the complete guide on how to define the problem in machine learning.
2. Data strategy and sources
Design criterion: data does not come ready to train. Before coding you need to decide where it comes from, who labels it, how often it is updated and what happens when it arrives corrupted or incomplete. This decision affects the architecture of the entire system; it is not an implementation decision.
You can explore examples and sources in the where to get data section or in the complete guide on how to find and prepare data for your ML project.
3. Model type selection
Design criterion: model selection is a conceptual design decision before it is a technical one. Is your problem about prediction or clustering? Do you have labeled data or not? The answers to these questions determine the model type —classification, regression, clustering— before you open a notebook.
You can see how to make this decision in the choose model type section. The technical implementation is covered in the construction module.
4. Success metrics before training
Design criterion: defining accuracy as a success metric without context is a design error, not an implementation one. You need to decide which technical metric corresponds to the business objective: F1, AUC, RMSE, precision vs recall, and what minimum acceptable value it has before seeing the first results. If you do not define this before training, you do not know when to stop.
You can go deeper in the define metrics section or in the complete guide on model evaluation.
5. System scope and constraints
Design criterion: latency, inference cost, retraining frequency, data privacy. These constraints are not decided by the model, they are decided by the system design. Ignoring them produces models that work in Jupyter and fail in production. The scope defines the limits of the system: what goes in, what comes out, what happens when the model does not know.
You can see how to define this in the scope and constraints section or in the complete system design guide.
6. Production criteria
Design criterion: a model in production is a software system with all its implications, such as versioning, monitoring, alerts, rollback. Designing this before training forces you to build the model with those constraints in mind from the start. This is not a DevOps decision. It is a design decision that affects how you train.
You can see how this is implemented in practice in the construction module, where we develop the production design in detail.
Finish your project already
You've taken courses… but don't know how to apply it
92% of data professionals unblock their projects by seeing complete solved examples.
No sign-up · Instant access
How to define the problem in your machine learning project
Defining the problem in a machine learning project is a technical decision disguised as an administrative one. It is the step most often skipped and the one that destroys the most projects.
For problem definition, this Google article shows that the tests we set up to validate our system are key, but how are you going to set them up if you have not defined the problem first?
For example, some time ago I advised a project related to student dropout. When I received the project, the classification metrics were practically equivalent to those of a random classifier. They had already tried several models and none seemed to work.
At that point I suggested taking a step back. It can feel like wasting time, but in this case it was what saved the project.
The first thing I asked was:
- Can you clearly define the outcome you want to predict?
- Does that outcome impact a concrete business metric?
The answer revealed the problem.
The model was trying to predict whether a student was enrolled or not in a given period. But that target completely ignored time. It did not compare the student's status between consecutive periods.
And there was the error.
Dropout is not a state, it is a change.
It does not matter if a student is not enrolled today; what matters is whether they stopped being enrolled compared to the previous period.
For example: if a student appears as "not enrolled" in two consecutive periods, the model treated it as if they had not dropped out. But in reality, that student may have dropped out earlier. The model had no way of knowing because the target did not capture the transition.
In other words, the problem was not the model. It was the definition of the target.
We solved it by redefining the target variable using temporal information: instead of predicting a state, we moved to modeling the change between periods. This involved feature engineering and reconstruction of the target from enrollment sequences.
With that adjustment, and using the same data, the model improved its metrics by more than 30%.
What was failing was not the model. It was the problem definition.
This is exactly the type of error a design flowchart seeks to avoid: trying to model something that is not yet well formulated. Until we defined dropout as a change between periods, there was no clear machine learning problem.
Once that adjustment was made, the problem naturally becomes a classification task. And only at that point does it make sense to talk about models.
With the problem well defined, we can now move on to the next design decision: selecting the model type.
Where to get data for your AI project before building the model
How to get started in machine learning almost always depends on a question that no course answers: where will the real data come from once you leave the practice dataset?
When you work with real problems, data is almost never ready to train on.
In fact, it is often not even structured. You encounter PDFs, Excel files and, at best, a more or less organized database.
And that is not a minor problem. It is a design decision.
Because before coding you need to understand where the data comes from, who generates it, how often it is updated and what happens when it arrives incomplete or with errors.
This involves engineering work: defining data dictionaries, understanding the relationships between variables and designing structures that make sense for the problem you want to solve.
In a project I developed, we were working with operational reports that were not designed for analysis. We had to completely redesign the data structure to be able to reconstruct the information consistently. It was not just cleaning data, it was designing how it should exist.
And that changed everything.
Because data is not a technical input. It is part of the machine learning system design.
That said, there are also scenarios where you simply do not have the data. In those cases, you need to know where to find it. Here are some useful sources by project type:
| Project type | Recommended source | Link |
|---|---|---|
| Finance | World Bank Open Data | data.worldbank.org |
| IMF Data | imf.org/en/Data | |
| Retail / e-commerce | Google Analytics (own data) | analytics.google.com |
| Kaggle | kaggle.com/datasets | |
| Health | WHO | who.int/data |
| CDC | data.cdc.gov | |
| Social sciences | INEGI | inegi.org.mx/datos |
| Data.gov | data.gov | |
| NLP / text | Hugging Face | huggingface.co/datasets |
| Common Crawl | commoncrawl.org | |
| Computer vision | ImageNet | image-net.org |
| Roboflow | universe.roboflow.com |
How to choose the model type without writing a single line of code
Before you start training models, the structure of your problem already tells you what type of model you need.
Going back to the example of student dropout, once the problem was defined, the next step was to choose the model type.
In this case, the problem was formulated as classification. We wanted to predict whether a student was going to drop out or not. That already narrows down the types of models that make sense to use.
We also had labels available, which made this approach viable from the start.
But the most important thing was not that.
The model had to integrate with how the university already worked. They operated with Excel. They were not going to set up complex infrastructure or use new tools.
That is why we chose something simple, small and easy to interpret. It was the first time they were implementing something like this, so clarity mattered more than sophistication.
And it worked.
This design decision is also aligned with Google's ML Rules about starting simple, especially when this type of system is being adopted for the first time.
This is a pattern that repeats often in real projects. The model type is not defined by the maximum possible performance, it is defined by the business constraints.
Before opening a notebook, there is a question every team should answer:
What type of model makes sense in the system you are actually going to build?
At this point we have the problem defined and the model type clear. Now comes the key question: how do we know if it actually works?
How to define success metrics before training your model
Another common design error in a machine learning project is not choosing the wrong algorithm. It is starting to train without having defined what it means for the model to work.
To explain it, here is another anecdote. While working with a finance company, the discussion was not about the model. It was about how to define whether it was actually working.
And that starts before training.
First we had to understand the business. The goal was not just to predict, it was to correctly separate customers according to their risk level. For example, how risk was distributed across percentiles or how well we distinguished between good and bad payers.
From there, we defined the business metrics.
Then came the key question: which machine learning metric best represents that? In some cases, metrics like AUC or accuracy could serve as an approximation, but only if they correctly reflected that risk separation the business needed.
Then we defined the threshold. It is not enough for the model to be "good", it has to exceed a minimum level that makes it useful in operations.
This process was repeated with other metrics. Each one had to make sense both from the model and from the business perspective.
Because here is the important point.
Not all the metrics you optimize in machine learning are the ones that actually matter in production. Some must be met in the model, but others live directly in the business system.
When you align both, the model stops being an experiment and becomes a useful tool.
How to define the scope and constraints of the system before coding
Scope is not a list of features. It is what defines what enters the system, what comes out and what happens when the model does not know.
And that is determined by constraints.
Before coding, there are at least four you need to have clear:
- Acceptable latency
- Data volume in production
- How often the model will be updated
- Privacy conditions
These are not last-minute technical decisions. They are design decisions that completely change the type of system you can build.
In my case, this was very clear in a thesis project where we had to generate navigation maps for robots.
We could use complex maps, even 3D representations. But there was a key constraint: the map had to live inside the robot.
That implied limited memory, low latency and the need to compute everything offline.
That single decision changed everything.
We ended up using metaheuristics. Some consider them part of machine learning, others do not. But what matters is not the label, it is that they met the system constraints.
The map had to be lightweight, fast to query and compact enough to run on the available hardware.
Here the model was not the starting point. It was a consequence of the constraints.
This happens constantly in real projects. You do not design the model and then figure out how to use it. You design the system, and that defines which model is possible.
And there is a question that sums all of this up:
Does this system need to respond in real time or can it work in batch?
How to take a machine learning system to production and make it work in practice
Taking a machine learning system to production is not just a technical problem. It is an adoption problem.
In many cases, the way you implement the system depends more on the organization's maturity than on the model itself. Integrating a model into a company that already works with data is not the same as doing it in one that is just taking its first steps.
For example, in some projects we have opted for simple solutions, such as exposing the model through a service that can be consumed directly from Excel. This reduces friction and facilitates adoption, because it does not force users to change the way they already work.
In other cases, when we seek greater control or learning, we have implemented standalone applications, deployed in the cloud or on internal servers. This makes it possible to isolate the system from the operational flow and better understand how it should integrate into the process.
And here is where a key point emerges: the success of a system does not depend solely on technology.
It depends on three things:
- People
- Processes
- And technology
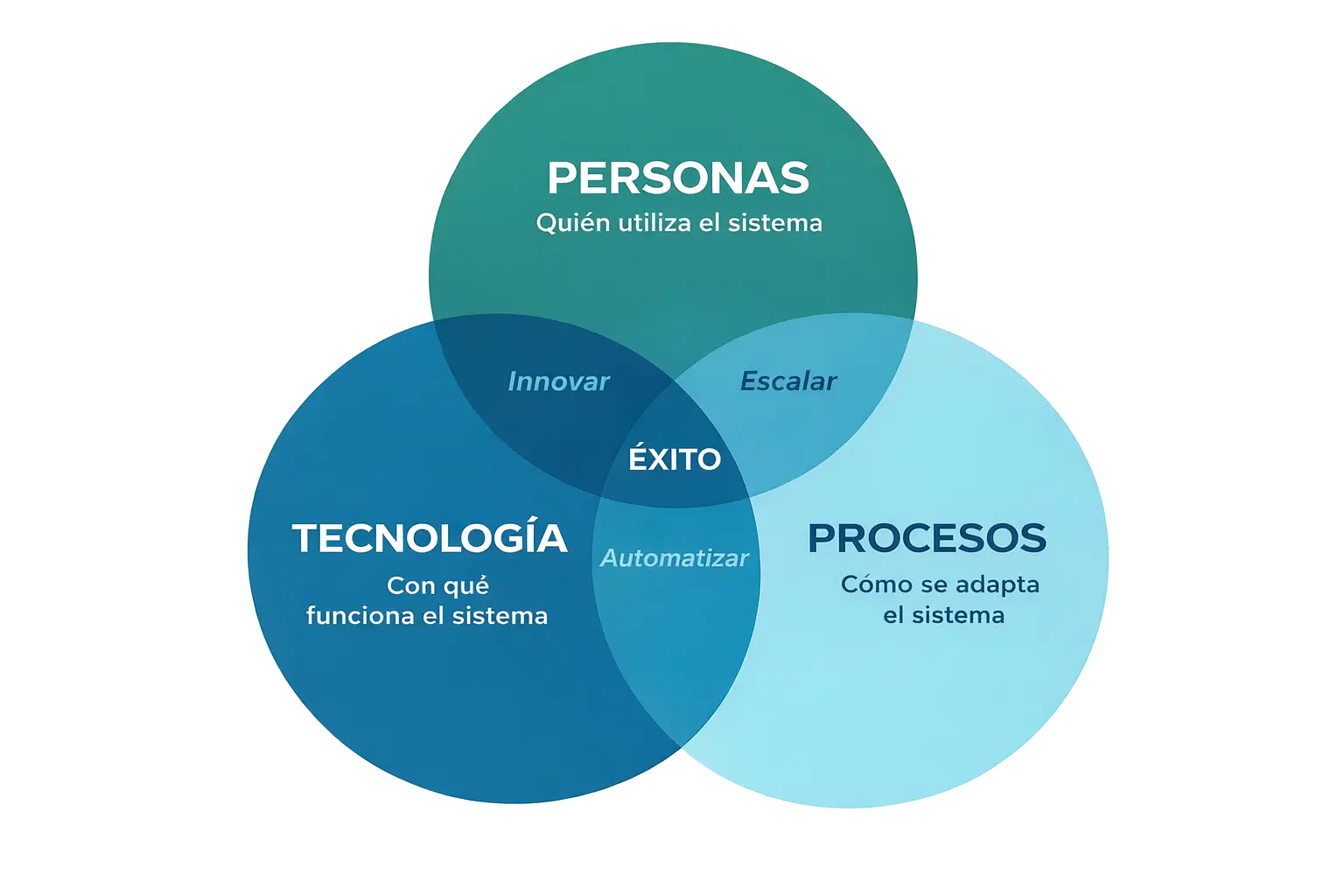
If people do not understand the system, they do not use it. If processes do not adapt, the system gets in the way. And if the technology does not fit, it simply does not scale.
This is something that repeats constantly. We have seen technically solid models fail because nobody uses them, and simpler ones generate real impact because they integrate well into the workflow.
There are also cases where adoption is more natural. For example, in computer vision systems, where the model can be integrated more automatically into the process, friction is usually lower.
But even there, the principle is the same: you do not design the model and then figure out how to use it. You design the complete system, including how it will be used in practice.
Because in the end, a model in production is not just working code. It is a system that someone has to use.
How this approach looks applied to real projects
Agriculture — Price prediction and nutritional optimization
Problem: estimating grocery prices and optimizing lowest-cost food combinations.
Before coding, three key decisions were made. First, define the problem as two layers: price prediction (regression) and constrained optimization. Second, structure the data as local time series, prioritizing real availability over complexity. Third, choose interpretable models that allowed explaining results to non-technical users.
Result: a system that not only predicts prices, but allows making practical decisions about food and cost in real contexts.
Industry — Cement strength prediction
Problem: estimating cement strength based on its composition and curing conditions.
Before coding, three key decisions were made. First, formulate the problem as continuous regression from the design phase, not as simplified classification. Second, define the relevant variables from the material's physics, not just from correlations. Third, prioritize model stability and generalization over maximum training performance.
Result: a model capable of predicting strength across different production scenarios, useful for quality control and decision-making on the production floor.
Frequently asked questions about machine learning projects from scratch
What is the first step to build an AI project from scratch?
The first step to build an AI project from scratch is to correctly define the problem. You need to understand what you want to predict and which business decision depends on that prediction.
How do I know what type of machine learning model I need for my problem?
To know what type of machine learning model you need, you first need to structure the problem. Whether it is prediction, classification or clustering, the model type is defined before coding.
What data do I need before starting an artificial intelligence project?
In an artificial intelligence project you need data that reflects the real problem. You need to define its origin, structure, update frequency and what to do if it arrives incomplete or incorrect.
When should I not use machine learning to solve a problem?
You should not use machine learning when the problem is not well defined or does not impact a real decision. If you cannot formulate it clearly, the model will not add value.
What is the difference between designing and building a machine learning system?
The difference between designing and building a machine learning system is that designing defines key decisions such as problem, data and metrics, while building means implementing models under those decisions.
If your machine learning project is for a thesis, start here
Applying machine learning in a thesis has constraints that industrial tutorials do not account for.
You have limited time, data that is not always ideal and a committee that does not only want results; they want to understand why you made each decision.
That completely changes how you design the project.
The scope is usually narrower. You do not need to solve the entire problem, you need to clearly define your contribution: what you are adding and why that is valid.
It also changes how you choose the model. In an academic environment, it is not enough for it to work. You have to methodologically justify why you chose that approach and not another.
And the same goes for metrics. Here it is not just about business impact, what matters is the validity of the result from a technical and academic standpoint.
Many people think that, because it is a thesis, the risk is lower.
But that is not the case.
If the project is not well defined, you fall behind. And falling behind means paying for another semester, another cycle. It ends up being a real cost.
That is why it is crucial that from the start you are clear about what problem you are solving, what your scope is and how you are going to demonstrate that your solution works.
If you are at that point and want clearer guidance, you can see how to structure your project step by step in the complete guide on how to use machine learning in your thesis.
And if you already have a project underway, whether academic or applied, and need help defining it or getting it unstuck, you can reach out to me directly. Often a single adjustment in the design changes the entire outcome.
Finish your project already
You've taken courses… but don't know how to apply it
92% of data professionals unblock their projects by seeing complete solved examples.
No sign-up · Instant access