/ Metodología ML / Definir el problema
Cómo Definir el Problema en un Proyecto de Machine Learning El primer paso cuando no sabes por dónde empezar
La mayoría se va directo al modelo. Y por eso se atasca. Definir bien el problema es lo que le da coherencia a todo lo que viene después.
Si llevas horas buscando datos, modelos o ejemplos y todavía no sabes por dónde empezar, es porque todavía no has definido qué quieres resolver.
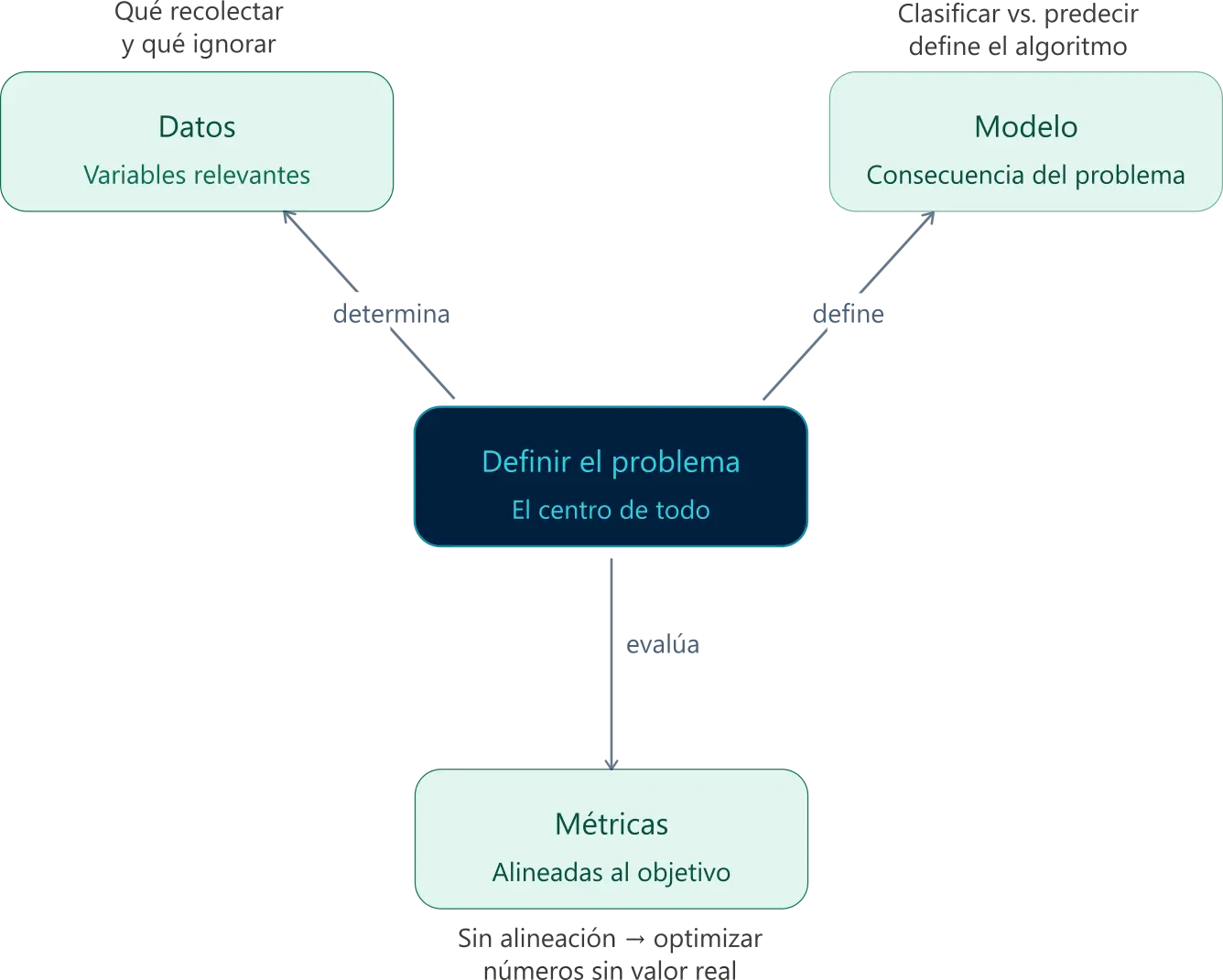
Cuando defines bien tu problema, sientas las bases estructurales de todo lo que viene después: qué vas a predecir, qué datos vas a necesitar, qué modelo puedes usar y cómo vas a evaluar si el resultado realmente tiene sentido.
Definir el problema es lo primero que hacemos cuando diseñamos proyectos de machine learning, porque es lo que le da coherencia a todo el proyecto, reduce el riesgo de fallar y evita perder el tiempo.
Esto lo he visto tanto en industria como en proyectos académicos. Por ejemplo, en un proyecto para la industria cementera relacionado con el diseño de la mezcla cruda, me indicaron que querían "optimizar la cantidad de yeso" para "optimizar el costo". El objetivo no era incorrecto, pero el problema no estaba suficientemente definido.
Empezar por el código, sin saber qué modelo sería más adecuado y sin haber definido una métrica de éxito global para el proyecto, hizo que el equipo solo estuviera probando sin llegar a un resultado interesante.
Por eso, sugerí ir un paso atrás: antes de modelar, tuvimos que trabajar directamente con el ingeniero de calidad para entender qué variable realmente representaba "optimizar", y bajo qué condiciones. Ese proceso cambió completamente la forma en la que el problema debía modelarse como una tarea de machine learning.
Tabla de contenido:
Cómo definir un problema de machine learning
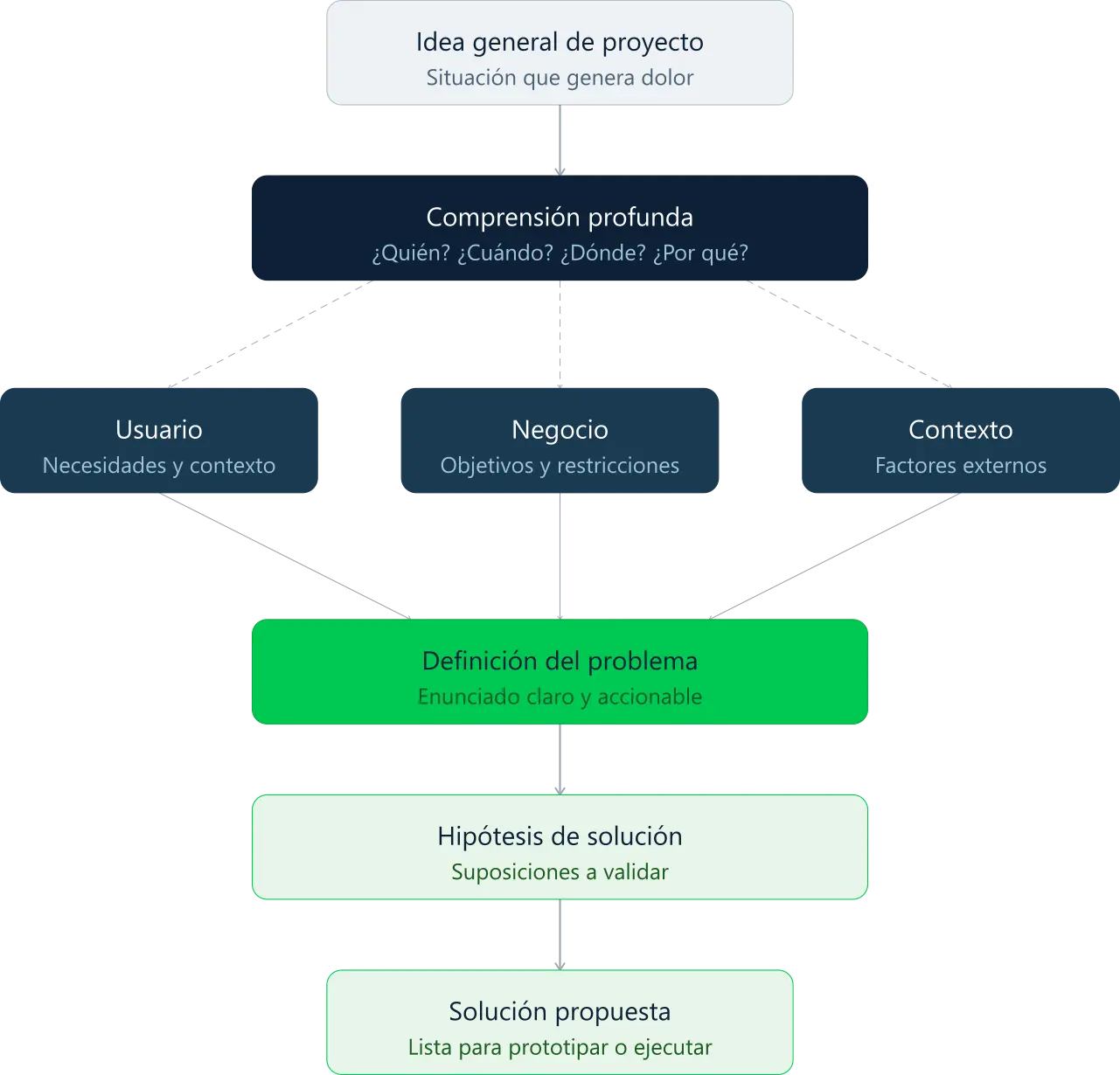
Para definir el problema usamos el método de problem framing. Este método traduce una idea general de proyecto en una tarea de ML con una variable objetivo, datos disponibles y una métrica clara.
Los pasos son:
- Idea general de proyecto: puede venir de un artículo que hayas leído, de algún negocio o de algo que hayas escuchado.
- Comprensión profunda del contexto: ¿quién tiene la dificultad? ¿Qué soluciones se han propuesto? ¿Qué entorno rodea al problema?
- Definición del problema: el enunciado que convierte tu idea en algo técnicamente resoluble. Aquí es donde se define qué significa resolver el problema. Cuando esta definición es clara, el resto del proyecto fluye con coherencia.
- Hipótesis y solución propuesta: con el problema definido, ya tiene sentido proponer un modelo. No antes.
Cómo identificar la idea general de tu proyecto de machine learning
Este es el primer paso, y también el más sencillo en apariencia.
Las ideas de proyecto suelen surgir de muchas fuentes: el propio razonamiento, la experiencia, la curiosidad o incluso la necesidad. En el ámbito académico, las ideas pueden venir de artículos científicos o trabajos de otros estudiantes. En el entorno profesional, nacen al intentar mejorar un proceso, resolver un problema o reducir ineficiencias.
Pero aunque este paso parezca simple, no es trivial. Las buenas ideas deben tener impacto. Ya sea que busques cumplir con los estándares de un comité académico o generar valor real en un negocio, el proyecto necesita justificar su relevancia.
Si aún no tienes claridad sobre ese impacto, no pasa nada. El proceso de definir el problema te ayudará a aterrizar y refinar la idea. Y algo importante: este proceso no es lineal. Es normal avanzar, retroceder y ajustar conforme entiendes mejor el problema. Una buena idea no nace perfecta: se construye.
Comprensión profunda del contexto para definir tu problema de machine learning
Aquí es donde empieza el trabajo real.
La comprensión profunda del contexto es lo que nos da las herramientas para definir correctamente el problema. Sin contexto, no hay claridad. Y sin claridad, el modelo, los datos o la arquitectura terminan respondiendo a preguntas mal planteadas.
Ese contexto depende del tipo de proyecto. En un entorno de negocio, implica entender al usuario, sus herramientas y sus objetivos. Como sugiere Jeremy Jordan, el problema debe definirse desde la perspectiva del usuario: qué está haciendo, qué busca lograr y qué dificultades encuentra, antes de intentar definir el problema como tal.
En el proyecto con la cementera, el usuario no era técnico y trabajaba principalmente en Excel para diseñar los primeros prototipos de mezclas. Desde el negocio, el objetivo era optimizar el uso de yeso para reducir costos sin comprometer la resistencia. Con ese contexto, fue más fácil definir el problema con claridad.
En el ámbito académico, el contexto se construye de otra forma. Aquí necesitas revisar la literatura, identificar el research gap y apoyarte en asesores. Lo importante es tener claro qué se ha hecho y qué sigue sin resolverse.
Termina ya tu proyecto
Ya tomaste cursos… pero no sabes cómo aplicarlo
El 92% de los profesionales de datos desbloquea sus proyectos al ver ejemplos completos resueltos.
Sin registro · Acceso inmediato
Cómo redactar la definición de tu problema de machine learning
Una buena definición no describe una idea. Describe una acción clara. Un enunciado accionable deja claro qué quieres predecir, con qué datos y cómo vas a medir si funciona.
En términos simples, tu definición debe incluir tres cosas:
- La variable objetivo.
- Los datos disponibles.
- La métrica de evaluación.
Sin estos tres elementos, el problema sigue siendo ambiguo. Según la guía de Google Developers, plantear bien el problema implica traducir una necesidad a una tarea concreta que un modelo pueda aprender. No se trata de decir "quiero predecir algo"; se trata de definir exactamente qué salida esperas y en qué contexto se va a usar.
El objetivo de negocio no es lo mismo que el problema de ML
El negocio habla en términos de impacto: reducir costos, mejorar calidad, evitar desperdicio. El problema de ML habla en términos de predicción: estimar una variable, clasificar un resultado, detectar un patrón. Traducir uno al otro es el trabajo real.
Siguiendo el caso de la cementera: "reducir costos" no es un problema de ML. Pero "estimar la cantidad mínima de yeso necesaria para cumplir con una resistencia objetivo" sí lo es.
Elegir la variable objetivo es la decisión más importante
Elegir la variable objetivo no es un detalle técnico. Es una decisión de diseño que define todo lo demás. Por ejemplo, en el contexto de la cementera puedes definir el problema de distintas formas:
- Predecir la resistencia a la compresión a partir de la composición del cemento. Eso es regresión.
- Predecir si una mezcla cumple o no con un umbral mínimo de resistencia. Eso es clasificación.
El objetivo de negocio no cambia. Pero el problema de ML sí. La documentación de Amazon Web Services muestra justo esto: un mismo objetivo puede tener múltiples formulaciones, y cada una lleva a decisiones distintas en datos, modelo y evaluación.
Ejemplo en negocio
| Elemento | Formulación A | Formulación B |
|---|---|---|
| Objetivo de negocio | Reducir costos en la producción de cemento | |
| Problema de ML | Estimar la cantidad mínima de yeso para una resistencia objetivo | Predecir la resistencia a la compresión a 28 días |
| Variable objetivo | Cantidad de yeso | Resistencia a la compresión |
| Datos | Composición de mezcla, condiciones de producción, resultados de laboratorio | Clínker, yeso, caliza, puzolana y otros componentes |
| Métrica | Desviación respecto a la resistencia objetivo | RMSE o MAE en la predicción de resistencia |
En ambos casos el contexto es el mismo. Lo que cambia es qué decides predecir. Un buen enunciado no es largo. Es claro. Y sobre todo, obliga a tomar decisiones.
Hipótesis y solución inicial en un proyecto de ML
Una vez que el problema está bien definido, ahora sí tiene sentido hablar de modelos. Antes de eso, cualquier intento es adivinanza.
Aquí entra la hipótesis técnica: una suposición informada sobre cómo resolver el problema con machine learning. No es el modelo final. Es una primera apuesta razonable que conecta lo que quieres predecir con los datos que tienes.
Una hipótesis técnica bien planteada responde algo como esto: con los datos disponibles, podemos predecir esta variable usando este enfoque y evaluar el resultado con esta métrica.
La solución inicial debe ser acotada. No busca ser perfecta. Busca validar si vas en la dirección correcta.
Ejemplo: el caso de la cementera
Con el problema ya definido —reducir costos optimizando el uso de yeso sin perder resistencia— puedes plantear distintas hipótesis:
- Regresión: predecir directamente la resistencia a la compresión a partir de la composición química del cemento.
- Clasificación: predecir si una mezcla cumple o no con un nivel mínimo de resistencia.
- Clustering: explorar patrones en las mezclas sin usar etiquetas, para entender comportamientos similares entre formulaciones.
El contexto es el mismo. El negocio es el mismo. Pero el problema de machine learning cambia por completo dependiendo de qué hipótesis eliges.
No necesitas resolver todo desde el inicio. Necesitas una primera versión que te permita aprender rápido. El paper Matching Problems to Solutions: An Explainable Way of Solving Machine Learning Problems propone una secuencia clara: entiendes el problema, defines cómo representarlo y luego eliges una solución coherente con esa formulación. Ese orden evita construir modelos desconectados del objetivo real.
Por qué tu modelo no mejora aunque el código esté bien
Si tu modelo no mejora, muchas veces el problema no está en el código. Está en cómo definiste el problema.
Métrica desalineada con el objetivo real
Uno de los errores más comunes es estar optimizando algo que no representa el objetivo real. En el caso de la cementera, podrías minimizar el error promedio de predicción de resistencia. Pero si fallas en los casos donde la resistencia cae por debajo del mínimo aceptable, el modelo no sirve en operación. La métrica técnica no estaba alineada con lo que el negocio realmente necesitaba.
Target mal definido
Si la variable objetivo no captura bien lo que quieres resolver, ningún modelo va a arreglar eso. En el mismo ejemplo: si defines como target la resistencia a 28 días pero la decisión crítica ocurre antes, estás optimizando algo que llega tarde. El problema era la definición del target, no el algoritmo.
Un caso documentado en Problem Formulation and Fairness muestra esto con claridad: un sistema con resultados pobres no fallaba por el modelo, sino por cómo se había definido el target. Cambiar esa definición cambió el resultado sin tocar el algoritmo.
Esto refuerza una idea clave: el rendimiento del modelo está limitado por la calidad de la formulación del problema. Si esto falla, todo lo demás también. Y aquí regresa el punto inicial: todo empieza con contexto y con una buena definición.
Preguntas frecuentes sobre cómo definir el problema en machine learning
¿Por qué es importante definir el problema antes de elegir un modelo de machine learning?
Porque la definición del problema determina qué variable vas a predecir, qué datos necesitas y cómo vas a medir el éxito. Sin una definición clara, incluso un modelo bien implementado puede producir resultados que no sirven en la práctica.
¿Qué es el problem framing en machine learning?
Es el método que traduce una idea general de proyecto en una tarea de ML con una variable objetivo, datos disponibles y una métrica clara. Sus pasos son: idea general, comprensión profunda del contexto, definición del problema e hipótesis de solución.
¿Cuál es la diferencia entre el objetivo de negocio y el problema de machine learning?
El objetivo de negocio habla en términos de impacto: reducir costos, mejorar calidad. El problema de ML habla en términos de predicción: estimar una variable, clasificar un resultado. Traducir uno al otro es el trabajo real de la definición del problema.
¿Qué debe incluir una buena definición de problema de machine learning?
Una buena definición debe incluir tres elementos: la variable objetivo que quieres predecir, los datos disponibles para entrenamiento y la métrica de evaluación que define el éxito. Sin estos tres elementos el problema sigue siendo ambiguo.
¿Por qué mi modelo de machine learning no mejora aunque el código esté bien?
Muchas veces el problema no está en el código sino en cómo se definió el problema. Los errores más comunes son una métrica desalineada con el objetivo real y un target mal definido que no captura bien lo que se quiere resolver.
Continúa con estos recursos del mismo nivel
- Cómo usar machine learning en tu tesis de pregrado o posgrado
- Datos y fuentes para proyectos de machine learning
O regresa al pilar principal sobre cómo diseñar un proyecto de machine learning antes de programar.
Si tienes un proyecto en marcha y no estás seguro de si el problema está bien definido, puedes escribirme directamente. Muchas veces ese es el ajuste que cambia todo el resultado.
Termina ya tu proyecto
Ya tomaste cursos… pero no sabes cómo aplicarlo
El 92% de los profesionales de datos desbloquea sus proyectos al ver ejemplos completos resueltos.
Sin registro · Acceso inmediato